Table of contents
Open Table of contents
Introduction
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.” — Rich Sutton, The Bitter Lesson (2019)
A year ago, I was deep into building handcrafted agentic workflows with LangGraph and teaching others to do the same. I was carefully orchestrating graphs of LLM calls, tools, and decision branches, and I genuinely believed in the pattern.
The pattern made sense. Models were powerful even then, but they weren’t powerful enough to take meaningful actions on their own without close supervision. Even when they could, most of us (myself included) didn’t trust them enough to let them. Handcrafted workflows gave you control: you decided the path, the model filled in the blanks.
I wasn’t alone. Everyone from startups to large enterprises was building this way. Box built AI-powered workflows with LangGraph and their API. Uber built an agentic RAG workflow for their internal systems. It was the responsible, pragmatic thing to do.
That’s changed. Both the models and our confidence in them have shifted significantly. And the way we build with them is shifting too. We are moving from handcrafted agentic workflows to agents operating inside harnesses. To understand why, it’s worth looking at where we started.
This post is an extended version of a talk I delivered at Yale in February 2026.
Workflows, Loops, and the Bitter Lesson
When I say “workflow” here, I mean something specific: a human-designed graph of nodes, edges, and conditions that routes an agent through a predetermined sequence of steps. LangGraph’s stateful graphs, n8n’s visual flow builder, custom orchestrators, that kind of thing.
Beyond the reliability and control arguments, there’s a practical reason workflows stuck around: they were easy to debug. When something broke, you knew exactly which node failed and why. That matters when you’re shipping to production.
But there’s a hidden cost. When you build a workflow, you’re essentially encoding human cognitive steps into code. Every edge case requires a new branch. Workflows become brittle and expensive to maintain as tasks get more complex. The workflow is the intelligence; the model just fills in blanks.
That’s the deeper problem: workflows cap agent autonomy. The model can’t surprise you, for better or worse.
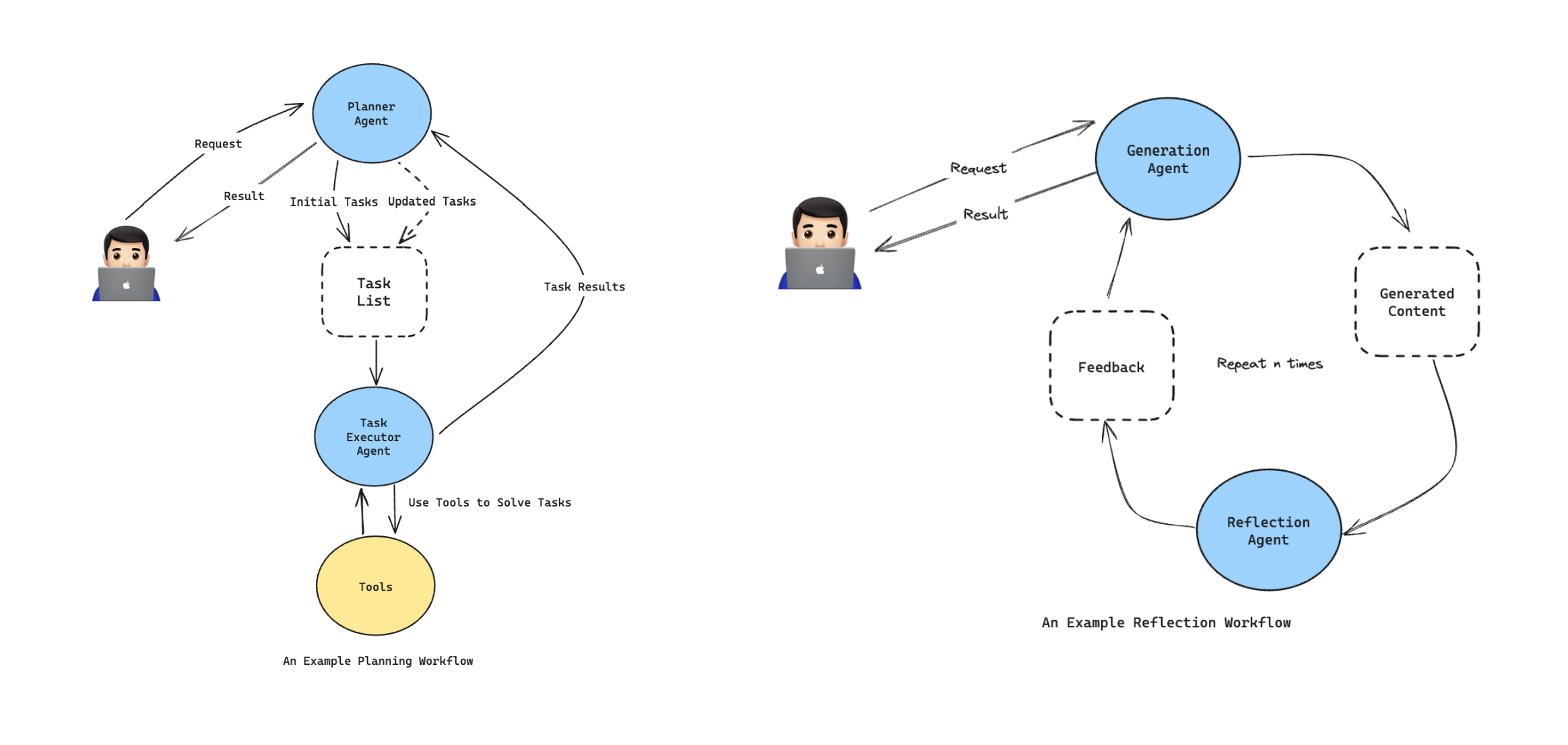 Planning Workflow and Reflection Workflow, two of the most commonly used workflow patterns
Planning Workflow and Reflection Workflow, two of the most commonly used workflow patterns
Why the Agentic Loop Is Fundamentally More Powerful
A workflow decides the path before execution. It’s a bet on your ability to anticipate every situation upfront.
The agentic loop (Perceive → Reason → Act → Observe) decides at runtime. The agent re-evaluates after every action, incorporating real feedback from the environment. It can handle novel situations, recover from unexpected failures, and take paths the designer never envisioned.
The loop doesn’t need to be told what to do when a document format is unexpected, an API returns an error, or a tool call produces a surprising result. It just adapts.
Workflows are open-loop: they execute a plan. The agentic loop is closed-loop: it continuously corrects based on what it observes. That difference is qualitative, and it matters a lot in practice.
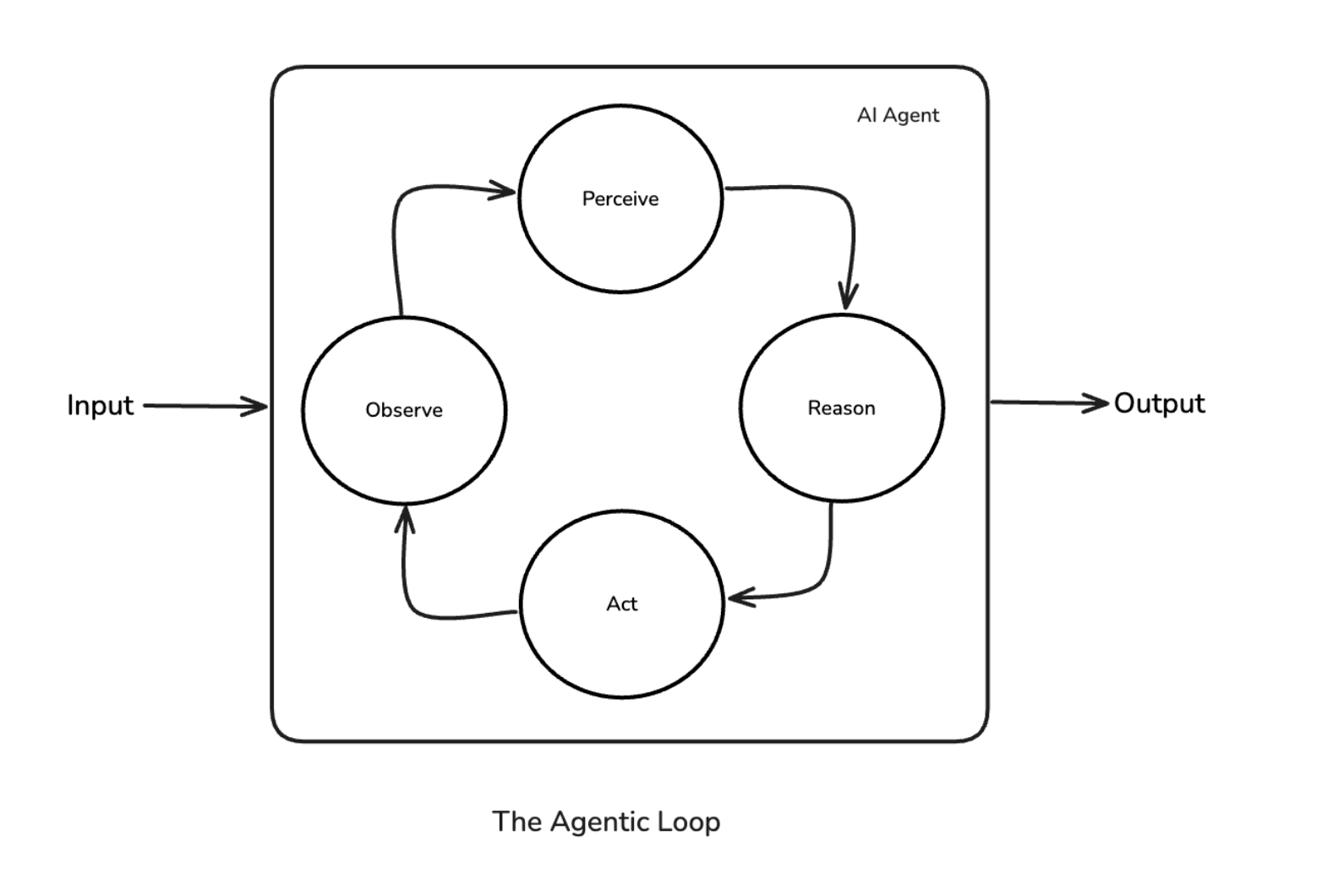 The Agentic Loop — Perceive → Reason → Act → Observe
The Agentic Loop — Perceive → Reason → Act → Observe
The Bitter Lesson, Applied
Rich Sutton’s 2019 essay argued that in AI, general methods leveraging computation always beat methods that encode human knowledge, eventually and by a large margin.
Handcrafted agentic workflows are the latest version of the same mistake. We’re encoding human reasoning (steps, branches, edge cases) into code when we could be trusting general capability and scale. Every hour spent mapping out a workflow graph is an hour spent codifying your current understanding of a task, which the model may already be able to surpass.
For truly agentic tasks, where the agent needs to reason, adapt, and recover on its own, workflows are a local optimum. They work until the task outgrows the graph you drew. (Workflows still have their place for well-scoped, predictable work; more on that later.)
A Personal Example: The Feature Extraction Workflow
At work, we built a feature extraction workflow using RAG. The task: given a vector database of financial documents (financial statements, balance sheets, etc.), extract specific data points like revenue, cost of goods sold, and current assets for a given year. Our data science team needed these features to run inference using their financial models.
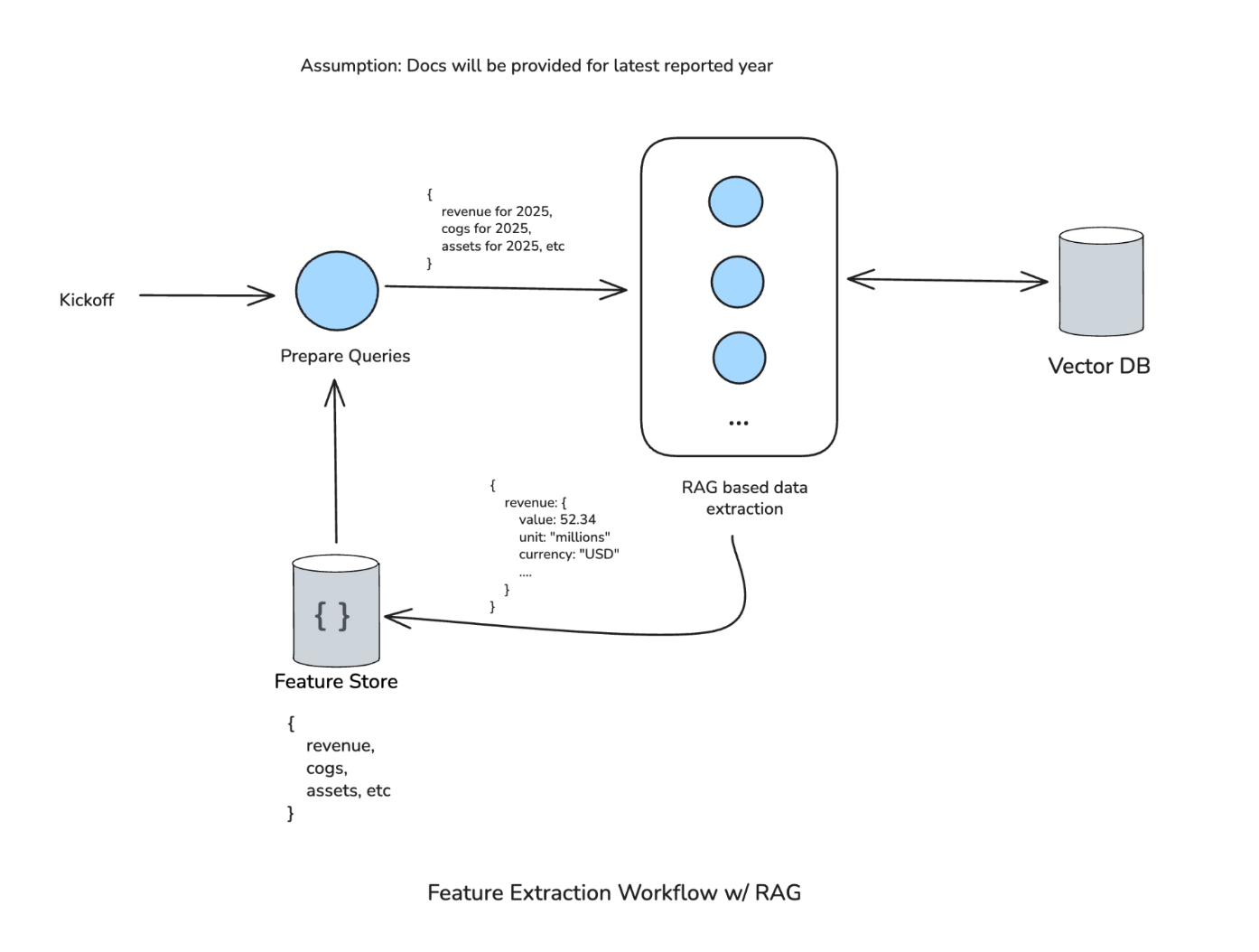 Feature Extraction Workflow V1 — the clean RAG workflow
Feature Extraction Workflow V1 — the clean RAG workflow
Version 1 was a clean workflow. A Prepare Queries step generates queries (“revenue for 2025”, “cost of goods sold for 2025”, etc.), feeds them into RAG-based extraction against the vector database, produces structured output (e.g., revenue: 52.34, unit: millions, currency: USD), and sends it to the feature store. The whole thing was linear and predictable, which is exactly what we wanted.
The first assumption that broke: we assumed documents would always be available for the latest reported year. They weren’t. The workflow couldn’t handle it.
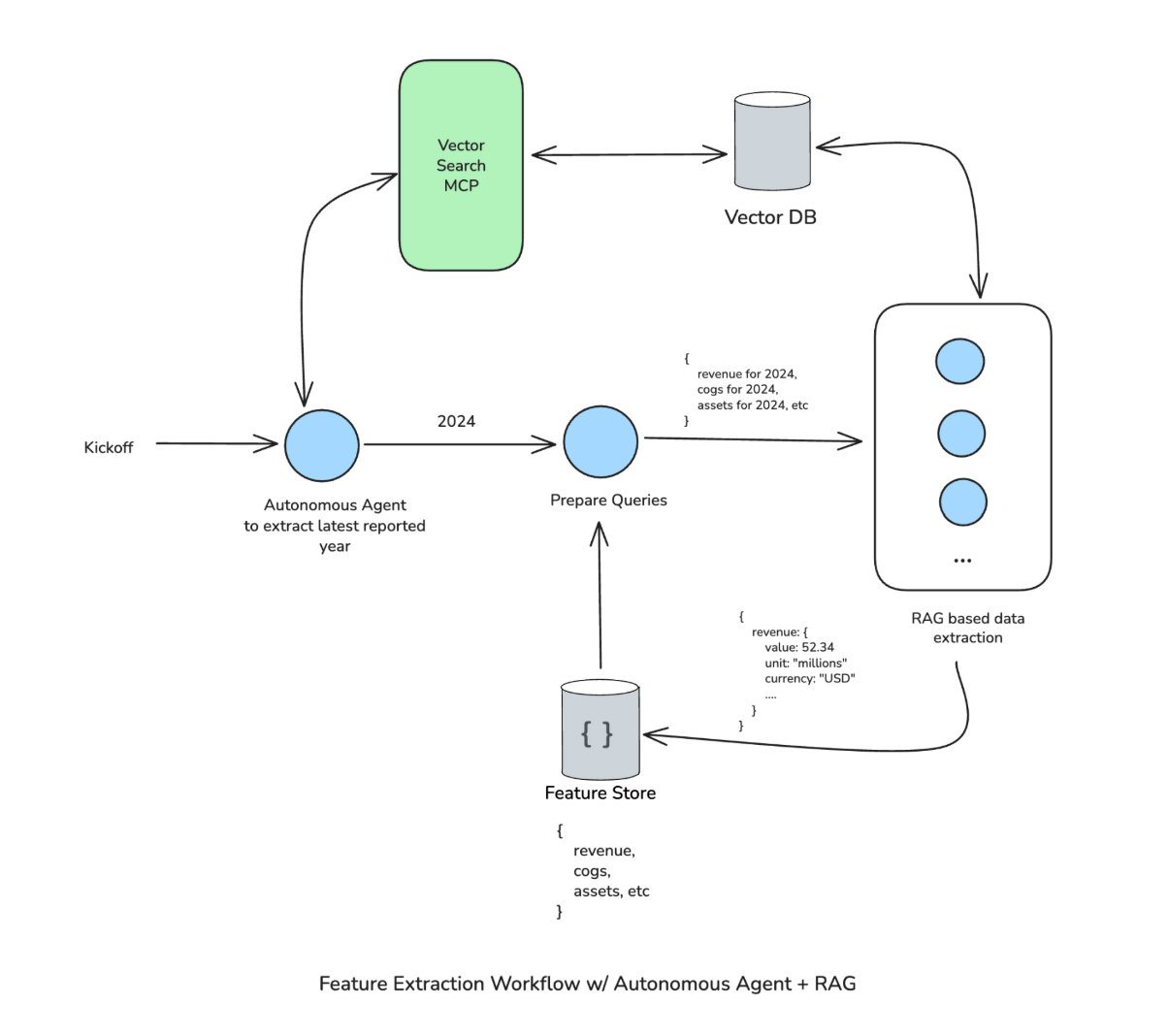 Feature Extraction Workflow V2 — workflow with autonomous agent patched at front
Feature Extraction Workflow V2 — workflow with autonomous agent patched at front
Version 2 patched this by adding an autonomous agent at the front. It uses Vector Search MCP to figure out the latest reported financial year in the collection, then passes that year to Prepare Queries. The rest of the workflow continues as before, so it was a fairly targeted fix.
Then it kept breaking. The data science team started trying to extract non-financial data (feed stock inventory, etc.) from the same workflow. Synonyms the workflow didn’t understand. The system needed the leeway to construct its own search queries and conduct as many searches as needed, refining and tweaking to get to the right answer. The workflow couldn’t provide that.
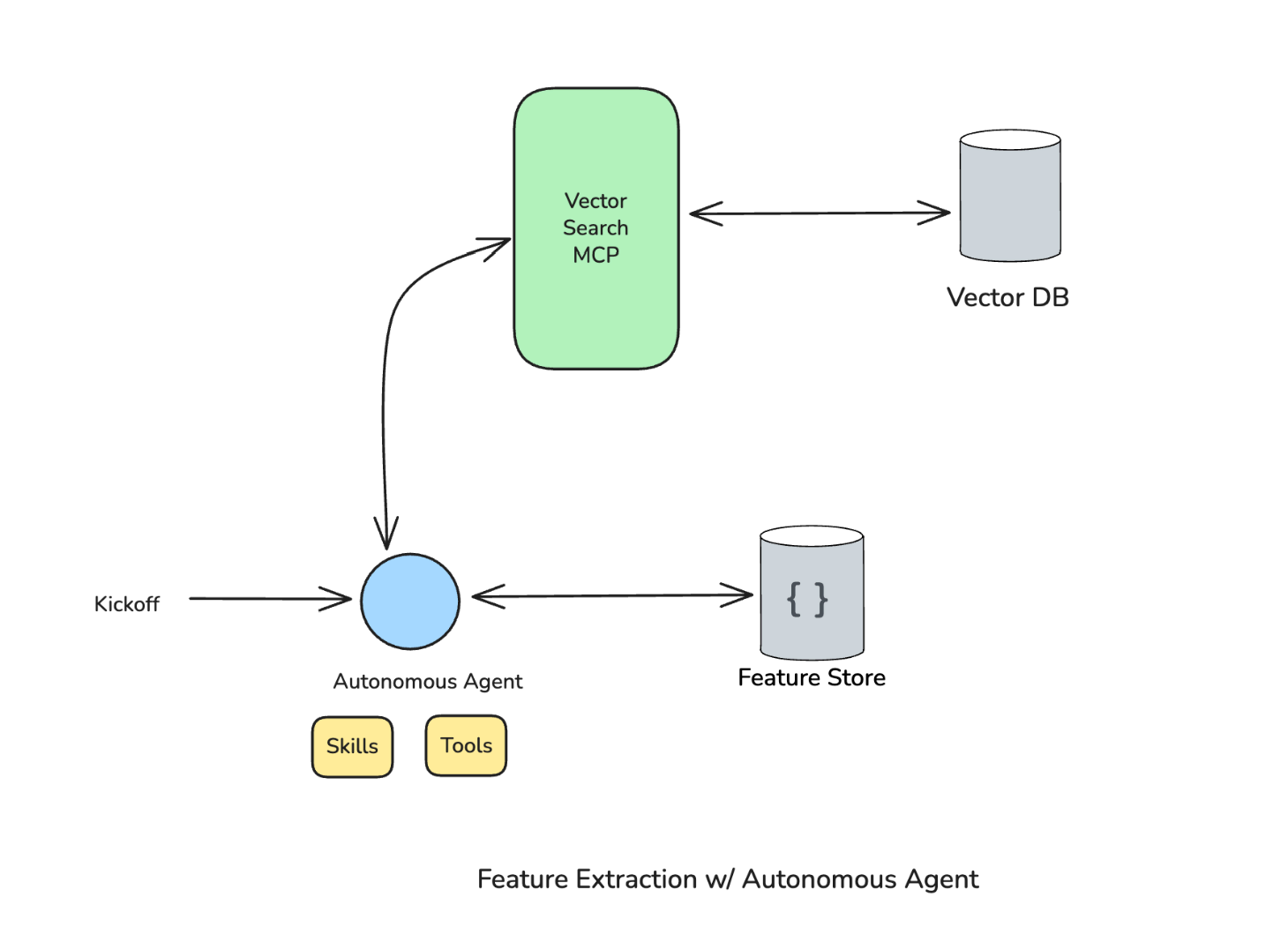 Feature Extraction V3 — autonomous agent at center with Skills, Tools, and Vector Search MCP
Feature Extraction V3 — autonomous agent at center with Skills, Tools, and Vector Search MCP
Version 3 put an autonomous agent at the center, with access to skills, tools, and the Vector Search MCP. The agent figures out everything on its own: which year to look for, what features to extract, how to handle edge cases. On our evaluation datasets, this version performed better than the previous ones.
Both V1 and V2 broke the moment we tried something outside the workflow’s expected scope. And that’s normal for software; you build a system to a spec, it works within that spec. The problem is that our expectations of what these intelligent systems should do have fundamentally changed. We expect them to behave like Claude Code, like Cowork, like Codex: to handle ambiguity, adapt to new requirements, and figure things out. A workflow scoped to a fixed set of assumptions can’t deliver on that expectation.
Here’s the thing about V3: the “workflow” logic didn’t disappear. It moved into skills, system prompts, and tool parsing. The structure is still there; it’s just expressed as instructions to the agent, and the agent decides how to apply them. That relocation is the pattern worth paying attention to.
Enter the Harness: How Agents Are Built Now
What Is a Harness?
A harness is an environment that wraps an agent and gives it what it needs to operate: a set of tools and capabilities, constraints and guardrails, memory and state management, and infrastructure for acting in the real world (browser, terminal, file system, APIs).
The key distinction from a workflow: a workflow tells the agent what to do, step by step. A harness gives the agent what it needs to figure that out itself.
The agent becomes a computer operator: a system that can navigate software, write and run code, browse the web, manage files. The harness is the platform; the model is the engine.
In my opinion, there’s still some sort of workflow behind the scenes. The agentic loop (Perceive → Reason → Act → Observe) is itself a sequence of steps. The harness sits on top of that loop, providing the tools, memory, and guardrails the loop needs to operate. The agentic loop is the definitive form of the workflow: general, adaptive, and determined at runtime. Everything else in the harness exists to support it.
Someone still has to build all of this: decide what tools the agent gets, how memory works, what constraints apply. That engineering work doesn’t go away.
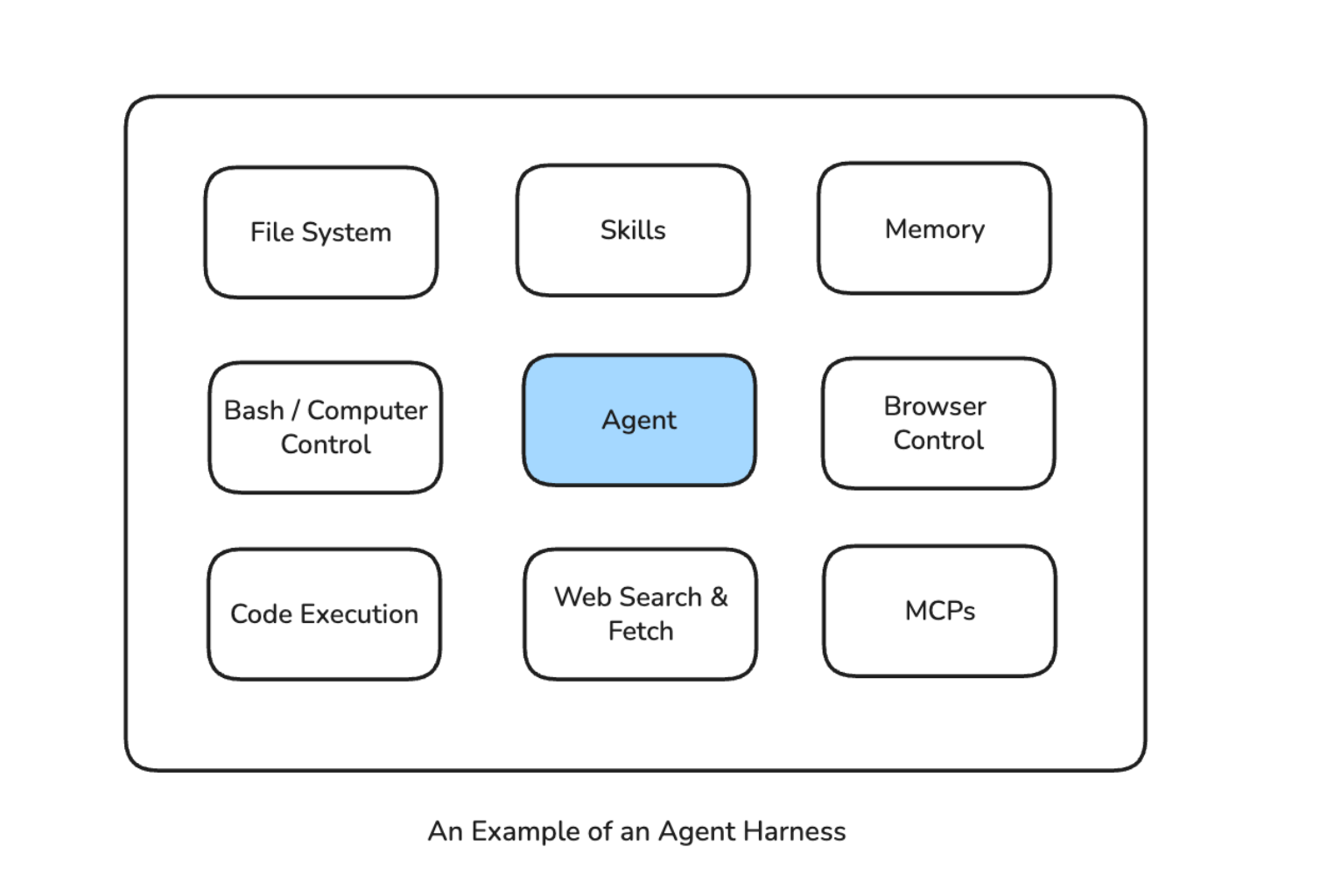 Agent Harness — Agent at center surrounded by File System, Skills, Memory, Browser Control, Code Execution, Web Search & Fetch, Bash/Computer Control, MCPs
Agent Harness — Agent at center surrounded by File System, Skills, Memory, Browser Control, Code Execution, Web Search & Fetch, Bash/Computer Control, MCPs
Where Harnesses Sit in the Tooling Landscape
It helps to think of agent tooling as layers, with the right level depending on what you’re building.
Raw API calls give you total flexibility and total responsibility. You manage state, memory, loops, everything.
Frameworks like LangChain, CrewAI, and LlamaIndex provide structure and abstractions, but you still make the architectural decisions: picking the memory system, configuring tools, defining orchestration; modular and swappable for the most part.
The runtime layer, exemplified by LangGraph, handles execution, state management, and durability. It sits between framework and harness, ensuring reliable execution of agent steps without prescribing the full environment.
Harnesses like Claude Code, OpenClaw, and LangChain Deep Agents are maximally opinionated. Memory, context management, the agent loop, tool access, safety checks: all baked in. You configure around the edges; the hard decisions are already made.
The LangChain ecosystem illustrates all three layers at once. LangChain (framework for composing agents) feeds into LangGraph (runtime for executing them reliably), which feeds into Deep Agents (harness for using them out of the box with batteries included: built-in planning tools, file system access, sub-agent spawning, memory persistence).
Understanding where you sit in these layers determines what you’re responsible for and what the tooling handles for you.
Real-World Examples of the Harness Paradigm
Claude Code
Claude Code is a general-purpose computer operator. It reads codebases, runs tests, edits files, and iterates. The “harness” here is terminal access, file system, bash execution, and context management. What makes it powerful is what the model has access to and how that access is managed.
Manus
Manus uses a Planner → Executor → Verifier architecture, an example of an agentic harness at scale. Each agent operates autonomously within its defined scope, with role specialization emerging from the harness design rather than rigid workflow graphs. The orchestration layer handles coordination; the handcrafted DAG is gone.
OpenClaw
OpenClaw is an open-source autonomous agent that runs locally on your machine, connecting LLMs with system tools and 50+ integrations: email, file system, calendar, shell commands, web browsing, external APIs. The harness pattern is visible here: the model sits at the center; OpenClaw provides the runtime, tool access, and messaging interface (Telegram, WhatsApp, Slack, etc.). The user gives a goal; the agent decides how to accomplish it.
NanoClaw, a lightweight offshoot (~500 lines of TypeScript built on the Claude Agent SDK), distills the pattern even further: a container where the core is just the agentic loop. As its creator put it, the goal is the “best harness” for the “best model.”
The Model and the Harness Are Both Load-Bearing
A common misconception: as models get more capable, the infrastructure around them matters less. A more capable model in a poorly designed harness is just a faster way to do the wrong thing.
The relationship is symbiotic. The model provides the reasoning and general capability; the harness determines what that capability can actually reach and do.
Models are rapidly commoditizing. Claude Opus 4.6, GPT-5.3, Gemini 3.1 Pro, DeepSeek are all capable. In February 2026, all three major providers hit near-parity on SWE-bench Verified, scoring within a percentage point of each other. Swapping models without rethinking the harness rarely produces proportional gains.
The whole system is what differentiates agent products. What tools does the agent have access to? How is memory managed across sessions? How are errors caught and recovered from? What guardrails and hooks shape its behaviour? The bottleneck shifts to the environment the model operates in, which means model selection is only one part of the investment.
Implications for Building Agents
The industry is already moving past workflows. Concretely, the work now looks like writing agents.md, claude.md, and system prompts that define how the agent should behave. Skills take this further: a SKILL.md file defines a task the agent can perform, and the skill folder can include scripts, templates, and reference files the agent uses at runtime. These are the new building blocks.
Context isolation is a good example of how the problems stay the same while the solutions change. In a workflow, you controlled context explicitly through graph design: each node received exactly the data it needed. In a harness, you solve this through the harness’s own opinionated patterns, like spawning sub-agents that handle specific subtasks in isolated contexts. The parent agent orchestrates; each sub-agent focuses on its piece without its context being polluted by everything else.
There’s a lot more to say about harness engineering as a discipline. I’ll cover that in a follow-up post.
Trade-offs
Harnesses aren’t a free lunch. The shift to more autonomous agents introduces real costs worth naming directly.
Latency and token consumption. The agentic loop is verbose by nature. Every Perceive → Reason → Act → Observe cycle burns tokens. A workflow with a fixed sequence of calls has predictable, bounded cost. An agent reasoning its way through a task can spiral into many more LLM calls than you’d expect, especially when it hits ambiguity or errors. At scale, this matters for both cost and response time.
Prompt injection gets worse. This is about external threats. In a workflow, the attack surface is isolated within individual nodes: each node calls the LLM with a narrow scope and may or may not have access to the full set of tools. In a harness, a single orchestrating agent has access to the entire environment. If a prompt injection lands in that agent’s context, it can potentially reach everything the harness provides: file system, code execution, external APIs, the lot. The blast radius of a successful injection is fundamentally larger.
Unintended autonomy. This is about internal risk: the agent acting in good faith but making the wrong call. A workflow’s rigidity accidentally constrains this; the agent can only do what the graph allows. A harness agent can take actions that are technically valid but operationally harmful: overwriting the wrong file, making an expensive API call in a loop, taking a path that’s correct in isolation but breaks something downstream. Without well-designed hooks, scope limits, and permission models, “the agent will figure it out” can become “the agent did something unexpected and we have no idea why.”
Reproducibility and debuggability. When a workflow fails, you know exactly which node broke. When a harness agent fails, the reasoning trace can be long, non-linear, and hard to reproduce, especially if the agent’s path depended on real-world state that has since changed. Observability tooling for agentic systems is still fairly immature.
Where Workflows Still Make Sense
If you’re building a complex application that makes multiple calls to an LLM in multiple places, not everything will be (or should be) an agent.
Take something like Grammarly. You need the speed to give your user instant feedback about their writing. You probably don’t need multiple LLM calls running in a loop to figure out what needs to be done. It’s a couple of well-defined steps in a workflow, and that’s the right architecture for it.
Workflows fit when the task is well-scoped, the steps are predictable, latency matters, and an agentic loop would be overkill. A two-step pipeline that classifies a document and extracts fields doesn’t need autonomy; it needs to be fast and cheap.
Knowing which problems call for a fixed path and which ones need an agent that can adapt is the real architectural decision. Most real systems will have both.
Conclusion
For the past year, the question driving most agent work was “what should my agent do next?” That’s a workflow question: it assumes someone (you) is designing the path. The question worth asking now is different: “what does my agent need to be capable of?”
That shift changes everything downstream: how you architect, what you invest engineering hours in, what you expect the model to handle on its own.
The agents that will matter in 2026 and beyond are the ones that can operate with genuine autonomy inside well-designed harnesses: with memory, tools, judgment, and the ability to adapt when the plan breaks down.
We’re still early. The harness pattern is young, the tooling is rough, and there’s real work to do on safety, observability, and trust. But the direction seems fairly clear: give agents better environments, and they’ll do better work. The engineering challenge now is building those environments well.
References
- Sajal Sharma, From Agentic Workflows to Agent Harnesses — Yale University Talk (February 2026)
- Rich Sutton, The Bitter Lesson (2019)
- Box Engineering, Building AI-Powered Workflows with LangGraph and Box API
- Uber Engineering, Enhanced Agentic RAG
- LangChain, Improving Deep Agents with Harness Engineering
- LangChain, Deep Agents
- Tony Kipkemboi, Agent Frameworks vs. Harnesses (LinkedIn)
- Sajal Sharma, Building AI Agents with LangGraph — O’Reilly