Table of Contents
Open Table of Contents
Introduction
Welcome to the third installment in my Agentic RAG series! Building upon the foundations laid in my previous posts on Introduction to Agentic RAG, Query Router Implementation, and Corrective RAG Implementation, this tutorial presents a comprehensive agentic RAG workflow that combines multiple sophisticated patterns to create a robust, self-correcting retrieval system.
In traditional RAG systems, we often encounter scenarios where:
- Retrieved documents are irrelevant or only partially answer the question
- A single retrieval source isn’t optimal for all query types
- The initial query formulation leads to poor retrieval results
- The system lacks the ability to recognize and correct its own failures
This post demonstrates how to build an advanced agentic RAG workflow that addresses all these challenges by incorporating:
- Query Routing: Directing queries to the most appropriate data source (vector database, web search, or direct LLM response)
- Document Relevance Grading: Evaluating retrieved documents for quality before using them
- Query Rewriting: Reformulating queries when initial retrieval fails
- Self-Corrective Mechanisms: Recognizing when no relevant information exists and responding appropriately
A github repository for this project can be found here. I recommend cloning the repository and running the code to see the results for yourself.
Architecture Overview
Our comprehensive agentic RAG workflow orchestrates multiple decision points and feedback loops to ensure high-quality responses. Here’s the complete flow:
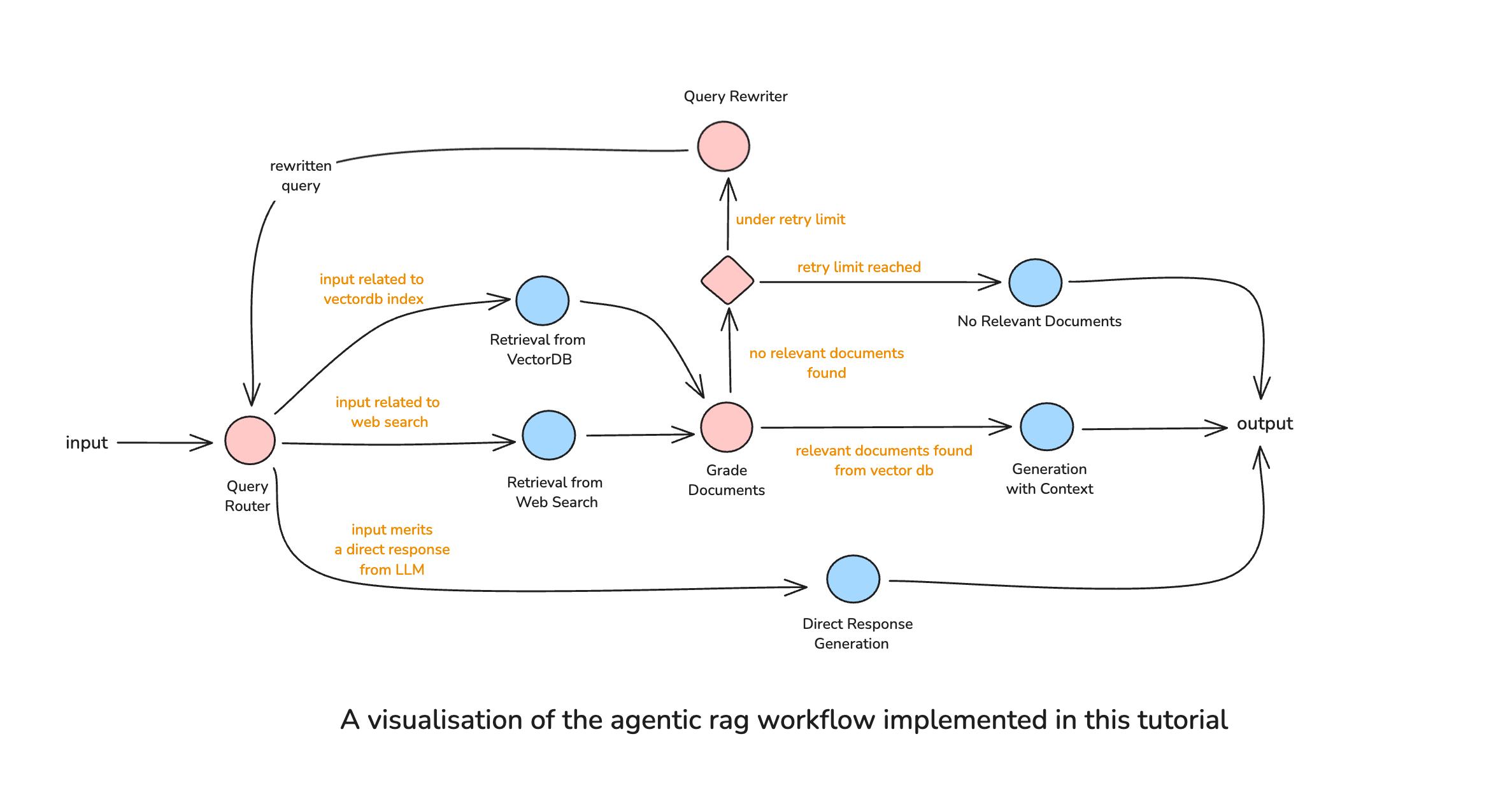
This architecture ensures that:
- Every query is analyzed to determine the optimal retrieval strategy
- Retrieved documents are validated before use
- Failed retrievals trigger query reformulation
- The system gracefully handles cases where no relevant information exists
- Direct responses bypass the retrieval pipeline entirely for efficiency
Implementation
Let’s build this comprehensive workflow step by step using LangGraph.
Setup and Environment
First, install the required dependencies:
pip install langgraph langchain langchain_openai langchain_community chromadb beautifulsoup4 tavily-pythonimport os
from typing import TypedDict, List, Literal, Annotated, Sequence
from typing_extensions import TypedDict
from langchain_chroma.vectorstores import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.retrievers import TavilySearchAPIRetriever
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.documents import Document
from langchain_core.messages import BaseMessage, AIMessage
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import END, StateGraph
from langgraph.graph.message import add_messages
from pydantic import BaseModel, Field
# Set your API keys
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["TAVILY_API_KEY"] = "your-tavily-api-key"Building the Vector Database
We’ll create a vector database from my own blog posts about RAG systems and LLM development:
# Load articles from sajalsharma.com
urls = [
"https://sajalsharma.com/posts/introduction-to-agentic-rag/",
"https://sajalsharma.com/posts/agentic-rag-query-router-langgraph/",
"https://sajalsharma.com/posts/corrective-rag-langgraph/",
]
# Load documents
print("Loading blog posts from sajalsharma.com...")
docs = []
for url in urls:
try:
loader = WebBaseLoader(url)
docs.extend(loader.load())
print(f"✓ Loaded: {url}")
except Exception as e:
print(f"✗ Failed to load {url}: {e}")
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
doc_splits = text_splitter.split_documents(docs)
print(f"\nCreated {len(doc_splits)} document chunks")
# Create vector store with persistence
vector_store = Chroma.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(),
collection_name="blog-posts",
persist_directory="chroma"
)
retriever = vector_store.as_retriever()Output:
Loading blog posts from sajalsharma.com...
✓ Loaded: https://sajalsharma.com/posts/introduction-to-agentic-rag/
✓ Loaded: https://sajalsharma.com/posts/agentic-rag-query-router-langgraph/
✓ Loaded: https://sajalsharma.com/posts/corrective-rag-langgraph/
Created 177 document chunksDefining the Graph State
The state object maintains all information as it flows through our workflow:
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
messages: Conversation history
query: Original user query
chosen_datasource: Selected retrieval source
retrieved_docs: Documents retrieved from any source
relevance_check: Whether documents are relevant
query_rewrite_count: Number of query rewrites attempted
final_answer: Generated response
"""
messages: Annotated[Sequence[BaseMessage], add_messages]
query: str
chosen_datasource: str
retrieved_docs: List[Document]
relevance_check: str
query_rewrite_count: int
final_answer: strCreating the Router Agent
The router analyzes each query to determine the best retrieval strategy:
# Initialize LLM
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Define routing schema
class RouteQuery(BaseModel):
"""Route query to appropriate datasource."""
datasource: Literal["vectorstore", "web_search", "direct_response"] = Field(
description="Choose between vectorstore for Sajal's blog content about RAG and agents, web_search for current events, or direct_response for general knowledge"
)
reasoning: str = Field(
description="Brief explanation for the routing decision"
)
# Router prompt
router_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert at routing user queries to the appropriate data source.
Based on the query, choose where to route it:
- vectorstore: For questions about Sajal's blog posts on agentic RAG, corrective RAG, query routing, or related RAG patterns
- web_search: For current events, recent developments, or information requiring real-time data
- direct_response: For general knowledge, definitions, or questions that don't require external data
Analyze the query carefully and make the best routing decision."""),
("human", "{query}")
])
# Create router chain
router_chain = router_prompt | llm.with_structured_output(RouteQuery)
def route_query(state: GraphState) -> GraphState:
"""Route query to the appropriate datasource."""
print("*** ROUTING QUERY ***")
query = state["query"]
router_result = router_chain.invoke({"query": query})
print(f"Routing to: {router_result.datasource}")
print(f"Reasoning: {router_result.reasoning}")
return {
"chosen_datasource": router_result.datasource,
"messages": [AIMessage(content=f"Routing to {router_result.datasource}: {router_result.reasoning}")]
}Implementing Retrieval Nodes
We need separate retrieval nodes for each data source:
# Vector store retrieval
def retrieve_from_vectorstore(state: GraphState) -> GraphState:
"""Retrieve documents from vector store."""
print("*** RETRIEVING FROM VECTOR STORE ***")
query = state["query"]
documents = retriever.invoke(query)
return {
"retrieved_docs": documents,
"messages": [AIMessage(content=f"Retrieved {len(documents)} documents from vector store")]
}
# Web search retrieval
web_search_retriever = TavilySearchAPIRetriever(k=3)
def retrieve_from_web(state: GraphState) -> GraphState:
"""Retrieve documents from web search."""
print("*** RETRIEVING FROM WEB SEARCH ***")
query = state["query"]
documents = web_search_retriever.invoke(query)
return {
"retrieved_docs": documents,
"messages": [AIMessage(content=f"Retrieved {len(documents)} documents from web search")]
}
# Note: prepare_direct_response node has been removed as it was redundantDocument Grading with Self-Reflection
This critical component evaluates the quality of retrieved documents:
# Document grading schema
class GradeDocuments(BaseModel):
"""Binary score for document relevance."""
binary_score: Literal["yes", "no"] = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# Grading prompt
grade_prompt = ChatPromptTemplate.from_messages([
("system", """You are a grader assessing relevance of retrieved documents to a user question.
Retrieved document:
{document}
User question: {question}
If the document is relevant to the user's original question, grade it as relevant.
Give a binary score 'yes' or 'no' to indicate relevance."""),
("human", "Grade the document.")
])
grade_chain = grade_prompt | llm.with_structured_output(GradeDocuments)
def grade_documents(state: GraphState) -> GraphState:
"""Grade the relevance of retrieved documents."""
print("*** GRADING DOCUMENTS ***")
query = state["query"]
documents = state["retrieved_docs"]
if not documents:
return {"relevance_check": "no_documents"}
# Grade each document
relevant_docs = []
for i, doc in enumerate(documents):
# Get a snippet of the document content for display
snippet = doc.page_content[:200].replace('\n', ' ').strip()
if len(doc.page_content) > 200:
snippet += "..."
grade = grade_chain.invoke({
"document": doc.page_content,
"question": query
})
if grade.binary_score == "yes":
print(f"✓ Document {i+1} graded as RELEVANT")
print(f" Snippet: {snippet}")
relevant_docs.append(doc)
else:
print(f"✗ Document {i+1} graded as NOT RELEVANT")
print(f" Snippet: {snippet}")
# Update state based on grading results
if relevant_docs:
return {
"retrieved_docs": relevant_docs,
"relevance_check": "relevant",
"messages": [AIMessage(content=f"Found {len(relevant_docs)} relevant documents")]
}
else:
return {
"relevance_check": "not_relevant",
"messages": [AIMessage(content="No relevant documents found")]
}Query Rewriting for Better Retrieval
When retrieval fails, we reformulate the query:
# Query rewriting prompt
rewrite_prompt = ChatPromptTemplate.from_messages([
("system", """You are a query rewriting expert. The user's original query didn't retrieve relevant documents.
Analyze the query and rewrite it to improve retrieval chances:
- Make it more specific or more general as appropriate
- Add synonyms or related terms
- Rephrase to target likely document content
- Consider the retrieval failure and adjust accordingly
Original query: {query}
Previous datasource: {datasource}"""),
("human", "Provide a rewritten query that will retrieve better results.")
])
rewrite_chain = rewrite_prompt | llm | StrOutputParser()
def rewrite_query(state: GraphState) -> GraphState:
"""Rewrite the query for better retrieval."""
print("*** REWRITING QUERY ***")
original_query = state["query"]
datasource = state.get("chosen_datasource", "unknown")
count = state.get("query_rewrite_count", 0)
# Rewrite the query
rewritten_query = rewrite_chain.invoke({
"query": original_query,
"datasource": datasource
})
print(f"Original: {original_query}")
print(f"Rewritten: {rewritten_query}")
return {
"query": rewritten_query,
"query_rewrite_count": count + 1,
"messages": [AIMessage(content=f"Query rewritten: {rewritten_query}")]
}Response Generation
We have different generation strategies based on the retrieval results:
# RAG generation prompt
rag_prompt = ChatPromptTemplate.from_messages([
("system", """You are an AI assistant. Answer the question based on the retrieved context.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, say that you don't know.
Keep the answer concise but comprehensive.
Context:
{context}"""),
("human", "{question}")
])
rag_chain = rag_prompt | llm | StrOutputParser()
def generate_with_context(state: GraphState) -> GraphState:
"""Generate answer using retrieved documents."""
print("*** GENERATING WITH CONTEXT ***")
query = state["query"]
documents = state["retrieved_docs"]
# Format documents for context
context = "\n\n".join([doc.page_content for doc in documents])
# Generate response
answer = rag_chain.invoke({
"context": context,
"question": query
})
return {
"final_answer": answer,
"messages": [AIMessage(content="Generated response with context")]
}
def generate_direct_response(state: GraphState) -> GraphState:
"""Generate response without retrieval context."""
print("*** GENERATING DIRECT RESPONSE ***")
query = state["query"]
direct_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Answer the question based on your knowledge."),
("human", "{question}")
])
direct_chain = direct_prompt | llm | StrOutputParser()
answer = direct_chain.invoke({"question": query})
return {
"final_answer": answer,
"messages": [AIMessage(content="Generated direct response")]
}
def generate_no_info_response(state: GraphState) -> GraphState:
"""Generate response when no relevant information is found."""
print("*** GENERATING NO INFO RESPONSE ***")
query = state["query"]
attempts = state.get("query_rewrite_count", 0)
answer = f"""I couldn't find relevant information to answer your question: "{query}"
I attempted to search {attempts + 1} time(s) across different sources and reformulated the query,
but no relevant documents were found. This might be because:
- The information isn't available in my current knowledge sources
- The topic is too specific or recent
- The query needs to be approached differently
Please try rephrasing your question or providing more context."""
return {
"final_answer": answer,
"messages": [AIMessage(content="No relevant information found")]
}Conditional Edge Decision Functions
def should_retry(state: GraphState) -> Literal["rewrite_query", "no_info"]:
"""Determine if we should retry with rewritten query."""
rewrite_count = state.get("query_rewrite_count", 0)
max_retries = 2
if rewrite_count < max_retries:
return "rewrite_query"
else:
return "no_info"
def route_after_grading(state: GraphState) -> Literal["generate", "retry_decision"]:
"""Route based on document grading results."""
relevance = state.get("relevance_check", "")
if relevance == "relevant":
return "generate"
else:
return "retry_decision"
def route_to_retrieval(state: GraphState) -> Literal["vectorstore", "web_search", "direct_response"]:
"""Route to appropriate retrieval method."""
return state["chosen_datasource"]Compiling the Complete Workflow
Now we assemble all components into a cohesive workflow:
def compile_workflow():
"""Compile the complete agentic RAG workflow."""
workflow = StateGraph(GraphState)
# Add all nodes
workflow.add_node("route_query", route_query)
workflow.add_node("retrieve_vectorstore", retrieve_from_vectorstore)
workflow.add_node("retrieve_web", retrieve_from_web)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("rewrite_query", rewrite_query)
workflow.add_node("generate_with_context", generate_with_context)
workflow.add_node("generate_direct", generate_direct_response)
workflow.add_node("generate_no_info", generate_no_info_response)
# Build the graph flow
workflow.set_entry_point("route_query")
# Routing from query router - direct_response goes straight to generate_direct
workflow.add_conditional_edges(
"route_query",
route_to_retrieval,
{
"vectorstore": "retrieve_vectorstore",
"web_search": "retrieve_web",
"direct_response": "generate_direct"
}
)
# After retrieval, grade documents
workflow.add_edge("retrieve_vectorstore", "grade_documents")
workflow.add_edge("retrieve_web", "grade_documents")
# After grading, decide next step
workflow.add_conditional_edges(
"grade_documents",
route_after_grading,
{
"generate": "generate_with_context",
"retry_decision": "rewrite_query"
}
)
# After rewriting, check retry limit
workflow.add_conditional_edges(
"rewrite_query",
should_retry,
{
"rewrite_query": "route_query",
"no_info": "generate_no_info"
}
)
# All generation nodes lead to END
workflow.add_edge("generate_with_context", END)
workflow.add_edge("generate_direct", END)
workflow.add_edge("generate_no_info", END)
return workflow.compile()
# Compile the workflow
app = compile_workflow()
print("✓ Comprehensive agentic RAG workflow compiled successfully")Output:
✓ Comprehensive agentic RAG workflow compiled successfullyTesting the Workflow
Let’s test our comprehensive workflow with different types of queries to demonstrate the various routing decisions and workflow paths:
def run_workflow(query: str):
"""Run the agentic RAG workflow and return the response."""
print(f"\n{'='*60}")
print(f"QUERY: {query}")
print(f"{'='*60}\n")
initial_state = {
"messages": [],
"query": query,
"query_rewrite_count": 0
}
result = app.invoke(initial_state)
return result["final_answer"]Test 1: Vector Store Query - Technical content about RAG patterns
This query asks about specific technical concepts covered in my blog posts.
Expected path: route_query → retrieve_vectorstore → grade_documents → generate_with_context
response1 = run_workflow("How does corrective RAG handle irrelevant documents?")
print(f"\nRESPONSE:\n{response1}")Output:
============================================================
QUERY: How does corrective RAG handle irrelevant documents?
============================================================
*** ROUTING QUERY ***
Routing to: vectorstore
Reasoning: The query specifically asks about 'corrective RAG,' which is a topic covered in Sajal's blog posts. The user is seeking an explanation related to a RAG pattern, making the vectorstore (containing Sajal's blog content) the most appropriate data source.
*** RETRIEVING FROM VECTOR STORE ***
*** GRADING DOCUMENTS ***
✓ Document 1 graded as RELEVANT
Snippet: This is where Corrective RAG (CRAG) comes into play. It enhances the traditional RAG framework by introducing a lightweight retrieval evaluator that assesses the quality of retrieved documents...
✓ Document 2 graded as RELEVANT
Snippet: The initial retrieval process is performed as in standard RAG. The agent assesses retrieved documents—checking for relevance, completeness, and contradictions. If needed, the agent triggers corr...
✓ Document 3 graded as RELEVANT
Snippet: Corrective RAG Corrective RAG introduces reflection mechanisms, allowing the system to refine its retrieval and response generation by reflecting the quality of the retrieval or generation steps. F...
✗ Document 4 graded as NOT RELEVANT
Snippet: Introduction What if chunks from a relevant document are not relevant enough for an LLM to answer a question in your RAG system?
*** GENERATING WITH CONTEXT ***
RESPONSE:
Corrective RAG handles irrelevant documents by evaluating the quality of the retrieved documents using a retrieval evaluator that assigns a confidence score. If documents are found to be irrelevant or low-confidence, the system can discard them to reduce noise in the generation step. Additionally, the agent may take corrective actions such as rewriting the query, performing another retrieval attempt, or fetching information from alternative sources to ensure more relevant and accurate context is provided to the language model.Test 2: Web Search Query - Current events and recent developments
This query asks about recent developments that require up-to-date information not available in the blog posts.
Expected path: route_query → retrieve_web → grade_documents → generate_with_context
response2 = run_workflow("What are the latest LangGraph features released in 2024?")
print(f"\nRESPONSE:\n{response2}")Output:
============================================================
QUERY: What are the latest LangGraph features released in 2024?
============================================================
*** ROUTING QUERY ***
Routing to: web_search
Reasoning: The query asks for the latest features of LangGraph released in 2024, which requires up-to-date information about recent developments. This information is best obtained through a web search.
*** RETRIEVING FROM WEB SEARCH ***
*** GRADING DOCUMENTS ***
✗ Document 1 graded as NOT RELEVANT
Snippet: Zach Anderson Jul 13, 2024 16:26 LangChain, a leading platform in the AI development space, has released its latest updates, showcasing new use cases and enhancements across its ecosystem. Accordi...
✓ Document 2 graded as RELEVANT
Snippet: We also have a new stable release of LangGraph. By LangChain 6 min read Jun 27, 2024 (Oct '24) Edit: Since the launch of LangGraph Cloud, we now have multiple deployment options alongside LangGra...
✓ Document 3 graded as RELEVANT
Snippet: langgraph: release 0.4.4 ; update for consistency; lint again; use list; lint + update; update; update; update; langgraph: fix drawing graph with root channel; langgraph: fix graph drawing for se...
*** GENERATING WITH CONTEXT ***
RESPONSE:
The latest LangGraph features released in 2024 include:
- Multiple deployment options with the introduction of LangGraph Cloud, alongside LangGraph Studio, now collectively referred to as the LangGraph Platform.
- Improvements in graph drawing, including fixes for drawing graphs with root channels and handling self-loops.
- Updates for consistency, code linting, and documentation enhancements.
- Addition of a gitmcp badge for simple LLM-accessible documentation.
These updates are part of the stable release 0.4.4 and subsequent improvements.Test 3: Direct Response Query - General programming knowledge
This query asks about general programming concepts that don’t require external data retrieval.
Expected path: route_query → generate_direct
response3 = run_workflow("What is the difference between a list and a tuple in Python?")
print(f"\nRESPONSE:\n{response3}")Output:
============================================================
QUERY: What is the difference between a list and a tuple in Python?
============================================================
*** ROUTING QUERY ***
Routing to: direct_response
Reasoning: This is a general programming knowledge question about Python data structures and does not require external data or specific blog content.
*** GENERATING DIRECT RESPONSE ***
RESPONSE:
In Python, **lists** and **tuples** are both used to store collections of items, but they have some important differences:
### 1. Mutability
- **List:** Mutable (can be changed after creation; you can add, remove, or modify elements).
- **Tuple:** Immutable (cannot be changed after creation; elements cannot be added, removed, or modified).
...(output condensed for brevity)
In short: Use a **list** when you need a mutable sequence, and a **tuple** when you need an immutable sequence.Test 4: Query Rewriting Example - Vague question requiring reformulation
This query is vague and likely won’t retrieve relevant documents initially, triggering the query rewriting mechanism.
Expected path: route_query → retrieve_vectorstore → grade_documents → rewrite_query → route_query → retrieve_vectorstore → grade_documents → generate_with_context
response4 = run_workflow("is agentic rag bad?")
print(f"\nRESPONSE:\n{response4}")Output:
============================================================
QUERY: is agentic rag bad?
============================================================
*** ROUTING QUERY ***
Routing to: vectorstore
Reasoning: The query is specifically about 'agentic RAG,' which is a topic covered in Sajal's blog posts. The user is likely seeking an informed perspective or analysis from those blog posts, making the vectorstore the appropriate data source.
*** RETRIEVING FROM VECTOR STORE ***
*** GRADING DOCUMENTS ***
✗ Document 1 graded as NOT RELEVANT
Snippet: What makes RAG Agentic? Agentic RAG introduces autonomy and adaptability into the standard RAG pipeline by allowing the system to actively control the retrieval process rather than relying on a fix...
✗ Document 2 graded as NOT RELEVANT
Snippet: Agentic RAG represents a significant evolution in retrieval-augmented generation, introducing autonomy, reasoning, and adaptability to improve how AI retrieves and generates information. By moving ...
✗ Document 3 graded as NOT RELEVANT
Snippet: An Introduction to Agentic RAG Skip to content Sajal Sharma Posts Tags About Me Search Go back An Introduction to Agentic RAG Published:M...
✗ Document 4 graded as NOT RELEVANT
Snippet: This modular, adaptable approach makes Agentic RAG vastly more powerful than traditional RAG, as it can tailor retrieval strategies in real time based on the nature of the query. In the next secti...
*** REWRITING QUERY ***
Original: is agentic rag bad?
Rewritten: What are the disadvantages, limitations, and potential problems with agentic RAG systems?
*** ROUTING QUERY ***
Routing to: vectorstore
Reasoning: The query asks about the disadvantages and limitations of agentic RAG systems, which is directly related to Sajal's blog posts discussing agentic RAG patterns and implementations.
*** RETRIEVING FROM VECTOR STORE ***
*** GRADING DOCUMENTS ***
✗ Document 1 graded as NOT RELEVANT
Snippet: Agentic RAG represents a significant evolution in retrieval-augmented generation, introducing autonomy, reasoning, and adaptability to improve how AI retrieves and generates information. By moving ...
✓ Document 2 graded as RELEVANT
Snippet: However, introducing agentic behavior comes with trade-offs. Additional decision points increase latency and computational costs, and maintaining prompts, retrieval strategies, and evaluation pipel...
✗ Document 3 graded as NOT RELEVANT
Snippet: retriever to an active reasoning system, Agentic RAG makes AI-powered retrieval more robust, context-aware, and verifiable, paving the way for more advanced, real-world-ready knowledge systems.
✗ Document 4 graded as NOT RELEVANT
Snippet: Retrieval-Augmented Generation (RAG) is a technique addresses the above issue by giving an LLM access to external knowledge. Instead of relying solely on their pre-trained data, RAG systems retrie...
*** GENERATING WITH CONTEXT ***
RESPONSE:
Agentic RAG is not inherently "bad," but it does come with important trade-offs and limitations:
**Main disadvantages:**
- **Increased latency and computational costs**: The additional decision points and processing steps make the system slower and more resource-intensive
- **Maintenance overhead**: Requires ongoing refinement of prompts, retrieval strategies, and evaluation pipelines
- **Added complexity**: More components mean more potential points of failure and harder debugging
Despite these challenges, agentic RAG offers significant benefits in terms of accuracy, reliability, and adaptability. For applications where these qualities are critical, the benefits typically outweigh the drawbacks. The key is to carefully consider whether the added complexity is justified for your specific use case.Future Improvements
Our agentic RAG workflow can be enhanced with several advanced capabilities to further improve its performance and reliability:
1. Multi-Source Parallel Retrieval: Instead of retrieving from one source at a time, the system could query multiple sources simultaneously (vector store, web search, knowledge graphs) and combine the results. This would reduce latency and provide more comprehensive coverage of potential information sources.
2. Response Grading Scoring: Adding a grading system to responses can add additional paths to the workflow, each leading to different actions based on the quality of the response, in addition to the existing paths based on the quality of retrieved documents.
3. Query Decomposition: For complex multi-part questions, the workflow could automatically break them down into simpler sub-queries, process each independently, and then synthesize the results. This would enable better handling of complex reasoning tasks that require multiple information retrieval steps.
Conclusion
This comprehensive agentic RAG workflow offers significant improvements over simpler agentic RAG systems. By combining intelligent routing, document grading, query rewriting, and self-corrective mechanisms, we’ve created a system that:
- Adapts to Different Query Types: Automatically selects the most appropriate retrieval strategy
- Ensures Quality: Validates retrieved documents before using them for generation
- Self-Corrects: Recognizes and recovers from retrieval failures
The modular design using LangGraph makes it easy to extend and customize the workflow for specific use cases. You can add new retrieval sources, implement more sophisticated grading mechanisms, or introduce additional self-reflective loops as needed. Keep in mind that LangGraph is just one of the many tools available for building agentic RAG workflows, and the choice of tool will depend on your specific needs and preferences.
As you implement this in your own projects, consider your specific requirements and adjust the components accordingly. The beauty of the agentic approach is its flexibility—you can start simple and progressively add more sophisticated behaviors and paths into the workflow as your needs evolve.