Table of contents
Open Table of contents
Introduction
What if chunks from a relevant document are not relevant enough for an LLM to answer a question in your RAG system?
Retrieval-Augmented Generation (RAG) represents a significant advancement in making Large Language Model (LLM) outputs more grounded and realistic by leveraging relevant documents for context, thus becoming a critical component of modern LLM systems.
Yet, it’s not without its shortcomings, especially when the retrieval mechanism sources less-than-ideal information. In my experience developing RAG systems for diverse clients, a recurrent issue has been the inadequacy of document chunks to fully address a query. I’ve observed that, quite often, providing LLMs with access to entire documents or expanding the context surrounding the targeted chunks can substantially enhance the model’s ability to formulate accurate responses. This underscores the necessity for a more nuanced approach to document retrieval and utilization within RAG frameworks, aiming to optimize the balance between relevance and comprehensiveness of the information provided to LLMs.
This is where Corrective RAG (CRAG) comes into play. It enhances the traditional RAG framework by introducing a lightweight retrieval evaluator that assesses the quality of retrieved documents and assigns a confidence score. This score then informs whether to proceed with the generated answer or seek further information, potentially through approaches such as web-search, or in the case of this document, passing in more context to the LLM.
In my latest experiment, I implemented CRAG using LangGraph, a powerful framework developed by the team at Langchain, for building complex AI workflows, using a graph-based approach. Follow along and this blog post will reinforce not only the value of CRAG to handle similar situations, but also the capability of LangGraph in orchestrating complex LLM workflows.
You can find a Python notebook for this post here.
Set Up
We’ll use langgraph (and thus, langchain) as our orchestration framework, OpenAI API for the chat and embedding endpoints, and ChromaDB for this demonstration.
Setting Up the Environment
The first step is to install the necessary libraries in your favourite environment:
pip install langgraph langchain langchain_openai chromadbImports
import os
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthroughDon’t forget to set your OpenAI Key!
os.environ["OPENAI_API_KEY"] = # enter your openai api key hereTransforming and Ingesting the Data
The source of the data is a verbose, markdown version of me resume. It has information on my work experience, education etc. You can check out the source file here.
Since the source is a markdown file, we can be a bit more clever than simply chunking it using character count. We’ll chunk the file using the markdown headers, ensuring that each chunk maintains its integrity, encapsulating the relevant data within.
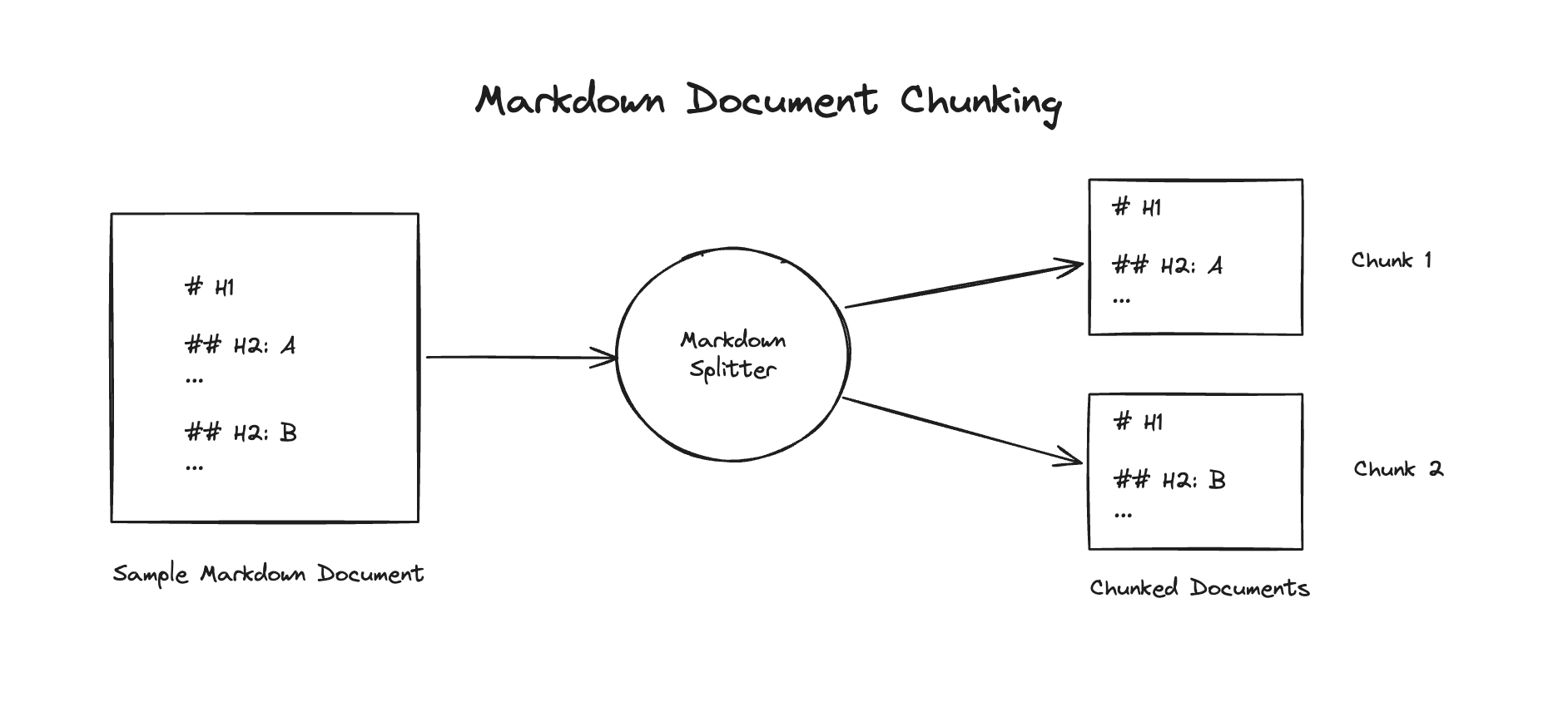
We’ll also create a vector store using ChromaDB, and a retriever object using the vector store.
# ingesting data
markdown_path = "source.md"
# read the markdown file and return the full document as a string
with open(markdown_path, "r") as file:
full_markdown_document = file.read()
# split the data into chunks based on the markdown heading
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on, strip_headers=False)
chunked_documents = markdown_splitter.split_text(full_markdown_document)
# create a vector store
embeddings_model = OpenAIEmbeddings()
db = Chroma.from_documents(chunked_documents, embeddings_model)
# create retriever
retriever = db.as_retriever()Results from a basic RAG chain
Defining the ChatOpenAI LLM object:
llm = ChatOpenAI(model="gpt-4-0125-preview", temperature=0)Defining a standard RAG chain using the retriever that we created previously:
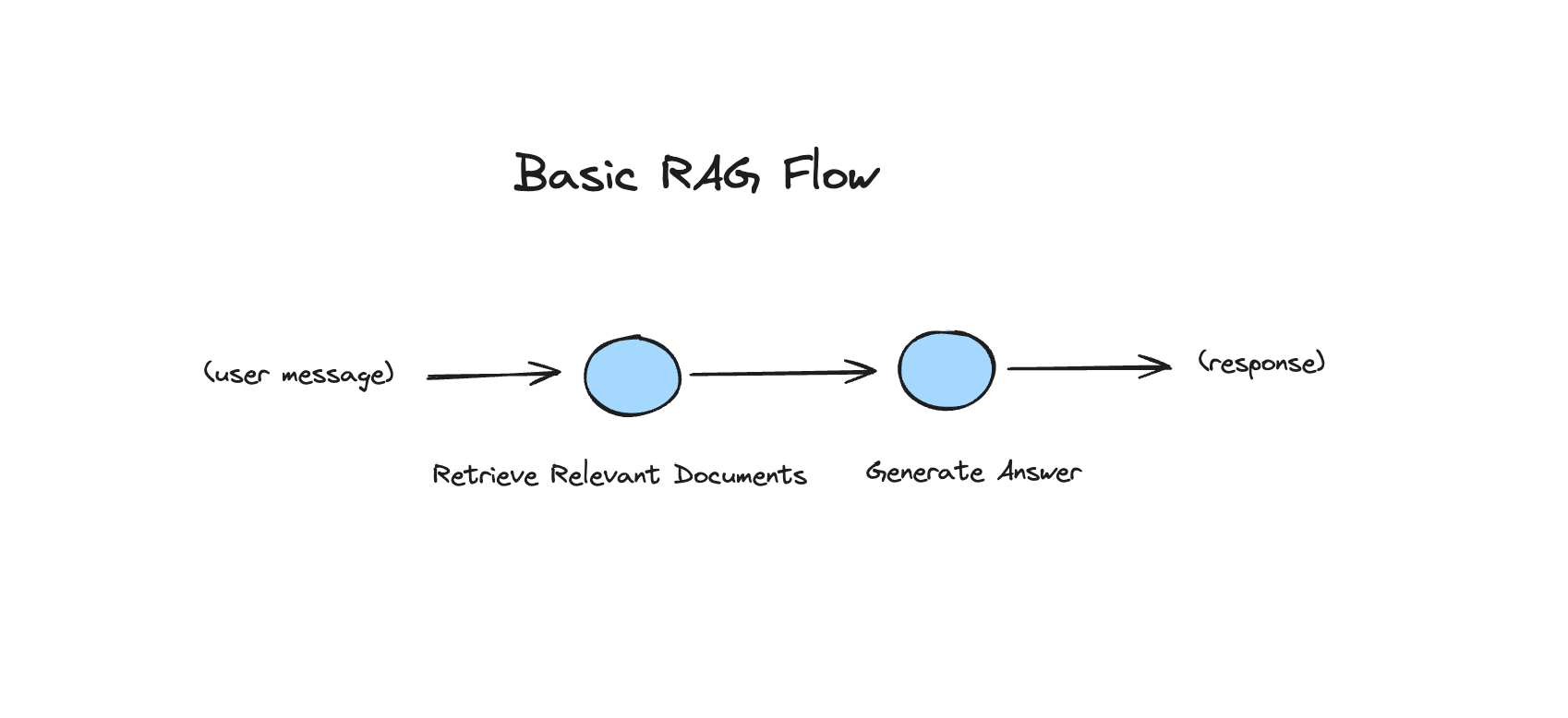
rag_prompt = """You are an AI assistant. Your main task is to answer questions people may have about Sajal.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
rag_prompt_template = ChatPromptTemplate.from_template(rag_prompt)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt_template
| llm
| StrOutputParser()
)Now, let’s check out a couple cases where the chain works fairly well. Intuitively, these would be questions where enough data exists within each retrieved chunk to completely answer a question.
rag_chain.invoke("When did Sajal graduate from University of Melbourne?")Output:
Sajal graduated from the University of Melbourne with a Master of Information Technology, majoring in Computing, in August 2016.
rag_chain.invoke("What did Sajal do at Unscrambl?")Output:
At Unscrambl, Sajal was a key member of the NLP Engineering team, where he helped enhance the natural language understanding of their business analytics platform, focusing on advancing Named Entity Recognition (NER), intent recognition, and ANNOY model functionalities. He developed the Natural Language to SQL system data preparation pipeline using NLTK and spaCy, significantly reducing manual effort and boosting system efficiency. Additionally, Sajal collaborated in designing and developing NLP-driven chatbot products and led the deployment of these solutions for clients across Asia, impacting over 100,000 monthly users.
Now, let’s see examples where our current RAG system would struggle. Think about cases where the answer to a question is not directly embedded in a chunk.
rag_chain.invoke("How many countries has sajal worked in?")Output:
The provided documents do not specify the exact number of countries Sajal has worked in. However, his education and mentoring activities suggest he has connections to Australia and India, and possibly interacts with international students globally through his role as a mentor at Udacity. Without more specific information on his professional work locations, it’s not possible to give a precise count of countries he has worked in.
Let’s check the documents that were retrieved from the vector database for the question.
retriever.get_relevant_documents("How many countries has sajal worked in?")Output:
[Document(page_content='# Sajal Sharma \n## Contact Info \n+65 9077-9093 |[email protected] | [LinkedIn](linkedin.com/in/sajals) | [GitHub](github.com/sajal2692)', metadata={'Header 1': 'Sajal Sharma', 'Header 2': 'Contact Info'}),
Document(page_content='## Languages \n- Hindi (Native or Bilingual)\n- English (Native or Bilingual)\n- German (Elementary)', metadata={'Header 1': 'Sajal Sharma', 'Header 2': 'Languages'}),
Document(page_content='## Activities \n- Mentor & Project Reviewer, Udacity: Coached 100+ international students enrolled in Data Science courses. Recognised as an elite mentor in 2021 with A+ mentor performance grade based on student feedback scores.\n- Mentor, STEM Industry Mentoring Programme, The University of Melbourne: Jul 2020 - Present\n- Creator, Data Science Portfolio: Github repo with 900+ stars showcasing various classical Data Science projects.', metadata={'Header 1': 'Sajal Sharma', 'Header 2': 'Activities'}),
Document(page_content='## Education \n**The University of Melbourne**\nMaster of Information Technology, Major in Computing\nMelbourne, Australia\nAug 2014 – Aug 2016 \n**Bharatiya Vidyapeeth University**\nBachelor of Computer Applications\nNew Delhi, India\nJul 2010 – Jul 2013', metadata={'Header 1': 'Sajal Sharma', 'Header 2': 'Education'})]Since there are no chunks that can directly answer the given question, the similarity search finds it hard to find relevant information.
Let’s look at another similar example:
# incorrect / incomplete result
rag_chain.invoke("list all the positions that sajal has held throughout his career")Output:
Throughout his career, Sajal has held the following positions:\n1. Mentor & Project Reviewer at Udacity\n2. Mentor at the STEM Industry Mentoring Programme, The University of Melbourne\n3. Creator of a Data Science Portfolio on GitHub\n4. Senior AI Engineer at Splore, a Temasek-backed AI startup (contracted via Unscrambl), Singapore
Again, seems like an incomplete answer. A better answer would have been to list the positions in the work experience section of the source document.
Building a Corrective RAG flow using LangGraph
With the problem set up, we’re finally ready to do some flow engineering.
We’re going to grade the retrieved documents using GPT-4, and based on the grades decide if the documents are relevant enough to generate an answer to the question, or if we need to pass in the whole document to give the LLM more context.
To do this, we’ll build a LangGraph graph, with nodes for retrieving documents given a query, grading the retrieved documents, and finally generating an answer using the retrieved chunks or the whole document.
Here’s what the flow will look like upon completion:
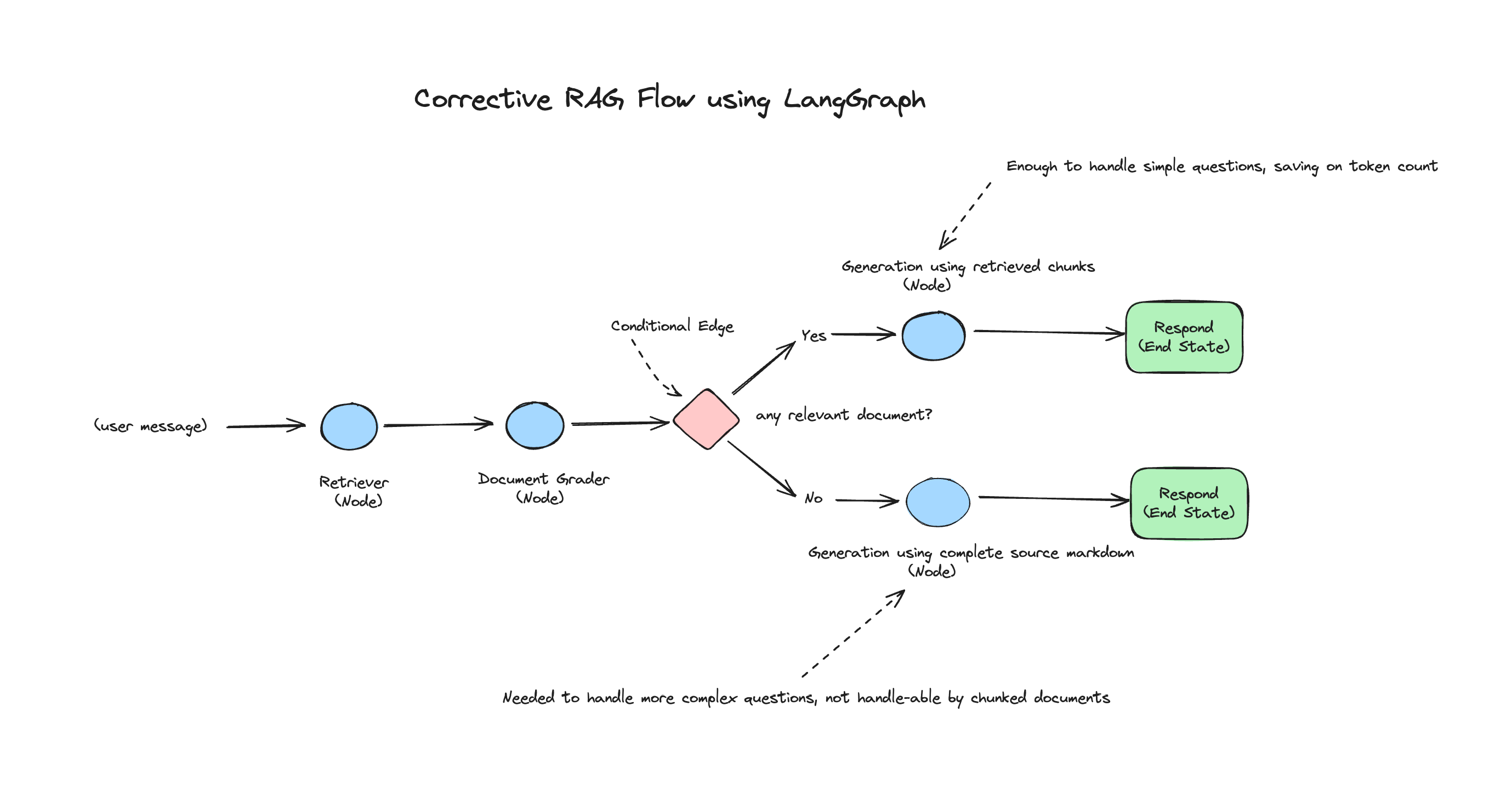
First, we begin by defining a data class that will hold the state of the graph. Think of it as a dictionary that contains data that is shared and used by nodes across the graph. A node modifies the state of the graph, i.e. updates the data in the state by adding, modifying or deleting.
For our purpose, the state will be a Python dictionary containing any data, but for production workflows, it’s prudent to define a more strict state class.
# Defining the state class which holds data related to the current state
from typing import Dict, TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
keys: A dictionary where each key is a string.
"""
keys: Dict[str, any]Now, let’s define the nodes of the graph. We need separate nodes for retrieving the documents, and for generating an answer based on the state. We’ll also add some print statements to our nodes so that we can track the flow.
We can begin by defining a node for retrieving the relevant documents (chunks) given a query:
def retrieve_documents(state):
"""Node to retrieve documents, by using the query from the state"""
print("---RETRIEVE DOCUMENTS---") # print statements to track flow
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.get_relevant_documents(question)
return {"keys": {"question": question, "documents": documents}}You can see that the node returns an updated state dictionary.
Next, let’s define a node to generate an answer, using the retrieved documents:
generation_answer_chain = rag_prompt_template | llm | StrOutputParser()
def generate_with_retrieved_documents(state):
"""Node to generate answer using retrieved documents"""
print("---GENERATE USING RETRIEVED DOCUMENTS---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
answer = generation_answer_chain.invoke({"question": question, "context": documents})
return {"keys": {"question": question, "response": answer}}The next piece of the puzzle is to define a node for grading the retrieved documents. I won’t go into detail about the code for this, but if you’re familiar with the concept of LLM tools and function calling, it should be straightforward to follow. If not, feel free to refresh your knowledge of these topics by visiting the langchain docs for function calling.
The node also determines, based on the grades, if there’s enough information in the chunks to generate an answer. It’ll add this information to the state.
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.utils.function_calling import convert_to_openai_tool
grader_prompt = """
You are a grader assessing relevance of a retrieved document to a user question. \n
Retrieved document: \n\n {context} \n\n
User Question: {question} \n
When assessing the relevance of a retrieved document to a user question, consider whether the document can provide a complete answer to the question posed. A document is considered relevant only if it contains all the necessary information to fully answer the user's inquiry without requiring additional context or assumptions.
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.
Do not return anything other than a 'yes' or 'no'.
"""
grader_prompt_template = PromptTemplate(template=grader_prompt, input_variables=["context", "question"])
# pydantic class for grade, to be used with openai function calling
class grade(BaseModel):
"""Binary score for relevance check."""
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
grade_tool_openai = convert_to_openai_tool(grade)
llm_with_grader_tool = llm.bind(
tools=[grade_tool_openai],
tool_choice={"type": "function", "function": {"name": "grade"}}
)
tool_parser = PydanticToolsParser(tools=[grade])
grader_chain = grader_prompt_template | llm_with_grader_tool | tool_parser
def grade_documents(state):
"""Node to grade documents, filter out irrelevant documents and assess whether need to run generation on whole document"""
print("---GRADE DOCUMENTS---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
filtered_documents = []
run_with_all_data = False
for doc in documents:
score = grader_chain.invoke({"context": documents, "question": question})
grade = score[0].binary_score
if grade == "yes":
print("---GRADE: FOUND RELEVANT DOCUMENT---")
filtered_documents.append(doc)
if not filtered_documents:
print("---GRADE: DID NOT FIND ANY RELEVANT DOCUMENTS")
run_with_all_data = True
return {
"keys": {
"documents": filtered_documents,
"question": question,
"run_with_all_data": run_with_all_data
}
}Now we need our final node, which generates an answer using the complete source document.
def generate_answer_using_all_data(state):
"""Node to generate the answer using the complete document"""
print("---GENERATING ANSWER USING ALL DATA")
state_dict = state["keys"]
question = state_dict["question"]
answer = generation_answer_chain.invoke({"question": question, "context": full_markdown_document})
return {"keys": {"question": question, "response": answer}}With the nodes in place, we need to define a conditional edge, which takes a look at the state, and determines the next node to be processed. Since we add data about our decision on how to generate an answer in the grader node, it will be used in this edge.
Defining the conditional edge:
def decide_to_use_all_data(state):
"""Conditional edge that decides the next node to run"""
state_dict = state["keys"]
run_with_all_data = state_dict["run_with_all_data"]
if run_with_all_data:
return "generate_answer_using_all_data"
else:
return "rag"All the pieces are in place and we’re ready to define the graph!
from langgraph.graph import END, StateGraph
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
keys: A dictionary where each key is a string.
"""
keys: Dict[str, any]
def compile_graph():
workflow = StateGraph(GraphState)
### define the nodes
workflow.add_node("retrieve", retrieve_documents)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate_answer_with_retrieved_documents", generate_with_retrieved_documents)
workflow.add_node("generate_answer_using_all_data", generate_answer_using_all_data)
### build the graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_use_all_data,
{
"rag": "generate_answer_with_retrieved_documents",
"generate_answer_using_all_data": "generate_answer_using_all_data",
}
)
workflow.add_edge("generate_answer_with_retrieved_documents", END)
workflow.add_edge("generate_answer_using_all_data", END)
### compile the graph
app = workflow.compile()
return appFinally, let’s compile our graph and define a function that can take in a question and run our complete flow.
app = compile_graph()
def response_from_graph(question):
"""Returns the response from the graph"""
return app.invoke({"keys": {"question": question}})["keys"]["response"]Let’s test out the graph workflow on questions that our basic RAG chain struggled with:
print(response_from_graph("How many countries has sajal worked in?")Print statement / logs outputs:
--RETRIEVE DOCUMENTS---
---GRADE DOCUMENTS---
---GRADE: DID NOT FIND ANY RELEVANT DOCUMENTS
---GENERATING ANSWER USING ALL DATAGraph output:
Sajal has worked in at least three countries: Singapore, the Philippines, and India. His work in Singapore is mentioned with OneByZero and Splore, a Temasek-backed AI startup. Additionally, he developed a proof of concept for a major bank in the Philippines and was a key member of Unscrambl’s NLP Engineering team in India.
A correct answer!
Let’s try the other question that didn’t produce great results:
print(response_from_graph("list all the positions that sajal has held throughout his career"))Graph output:
Throughout his career, Sajal has held the following positions:
- Lead AI Engineer at OneByZero (contracted via Unscrambl), Singapore.
- Senior AI Engineer at Splore, a Temasek-backed AI startup (contracted via Unscrambl), Singapore.
- Senior Machine Learning Engineer at Unscrambl, India.
- Machine Learning Engineer at Unscrambl, India.
Again, a much more complete answer, which is correct based on the given context.
But does our graph still work for cases where retrieved chunks are enough to answer the question?
print(response_from_graph("Has sajal created any popular github repositories?"))Print statement / logs outputs:
---RETRIEVE DOCUMENTS---
---GRADE DOCUMENTS---
---GRADE: FOUND RELEVANT DOCUMENT---
---GRADE: FOUND RELEVANT DOCUMENT---
---GRADE: FOUND RELEVANT DOCUMENT---
---GRADE: FOUND RELEVANT DOCUMENT---
---GENERATE USING RETRIEVED DOCUMENTS---Graph output:
Yes, Sajal has created a popular GitHub repository. His Data Science Portfolio on GitHub has garnered over 900 stars, showcasing various classical Data Science projects. This indicates a significant level of recognition and appreciation from the GitHub community.
Perfect!
Conclusion
In this blog post, we’ve explored the limitations of traditional Retrieval-Augmented Generation (RAG) systems and introduced Corrective RAG (CRAG) as a powerful alternative that enhances document retrieval through a lightweight evaluation process. Through practical examples and the use of LangGraph for orchestrating complex workflows, we’ve demonstrated how CRAG can significantly improve the accuracy and relevance of responses by dynamically adjusting the context provided to Large Language Models (LLMs).
This approach not only addresses the issue of inadequate document chunks but also highlights the importance of adaptability and precision in document retrieval processes. The success of CRAG in our experiments underscores its potential to refine and elevate the capabilities of RAG systems, making it a valuable tool for developers seeking to optimize LLM performance in various applications.
We can choose to be flexible and search the internet, or hit external knowledge bases based on the conditional edges in the graphs. We’ve merely scratched the surface of what’s possible with some creativity in implementing more advanced workflows with LangGraph.
References
- Yan, S.-Q., Gu, J.-C., Zhu, Y., & Ling, Z.-H. (2024). Corrective Retrieval Augmented Generation. arXiv. https://doi.org/10.48550/arXiv.2401.15884
- Self-Reflective RAG with LangGraph