Table of contents
Open Table of contents
Introduction
A Refresher on RAG
Large Language Models (LLMs) or Foundational Models, are powerful but have a fundamental limitation: they can only generate responses based on their training data, which might be outdated or incomplete.
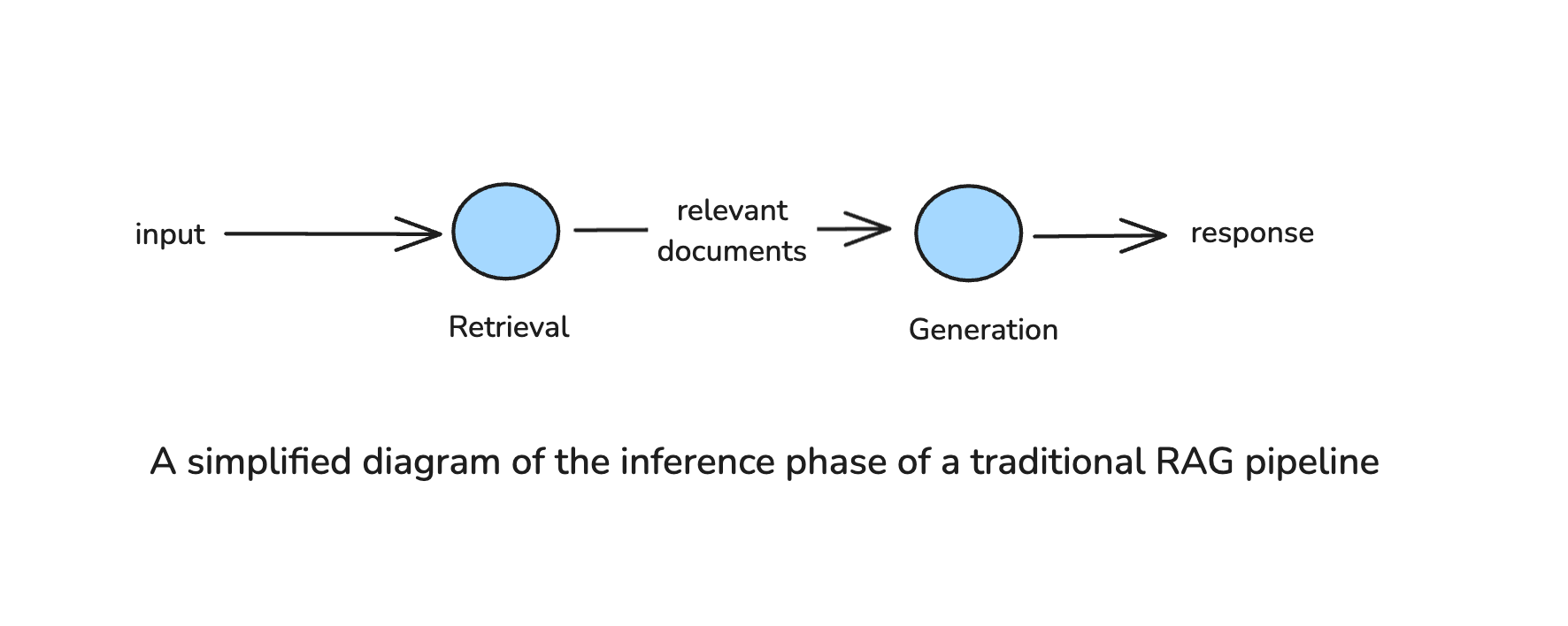
Retrieval-Augmented Generation (RAG) is a technique addresses the above issue by giving an LLM access to external knowledge. Instead of relying solely on their pre-trained data, RAG systems retrieve relevant documents from databases, vector stores, or APIs and feed them as additional context to the LLM before generating a response. This makes the model’s responses more accurate, up-to-date, and grounded in relevant contextual information.
Limitations of Traditional RAG
However, traditional RAG systems, like the one described above, have limitations. The pipeline is typically fixed: when a query comes in, it executes a single round of retrieval from a predefined external source and then generates a response using the retrieved data. This means the system can’t easily adjust if the first retrieval attempt doesn’t find what’s needed. If the retrieved documents are irrelevant or incomplete, the system has no way to refine its search or attempt a different retrieval strategy—it simply generates a response based on whatever information was returned.
Furthermore, traditional RAG systems lack the ability to select the most appropriate knowledge source from multiple external sources. Without a mechanism to determine the intent of a query, the system treats all queries the same way, retrieving from a fixed index or database regardless of whether a different source might be more suitable.
For example, consider a company with two knowledge sources:
- An internal policy database for HR-related queries.
- A web search API for general information.
If an employee asks, “What is our company’s remote work policy?”, the system might mistakenly retrieve general remote work articles from the web instead of the internal company database. Conversely, if someone asks, “What are the latest trends in remote work?”, but the system only searches internal documents, it will miss relevant industry insights.
You can imagine how both situations would lead to suboptimal results, or even “hallucinations” in some cases.
What are Agentic Systems?
In today’s world, an agentic system (also referred to as an AI Agent) refers to an LLM-powered system that exhibits autonomy in decision-making, selecting the best course of action based on its goals and available information. Unlike static systems that follow a fixed sequence of operations, agentic systems can assess situations, adapt their behavior, and iterate on their actions to improve results.
These systems are typically equipped with a range of tools they can use or actions they can take, but for the purpose of this blog post, we will not focus on the tool use capabilities of agentic systems.
A defining characteristic of agentic systems is the presence of agentic patterns—strategies that allow them to control, evaluate, and modify their workflow as needed. These patterns include, but are not limited to:
- Dynamic query analysis – Deciding how to handle an input based on its nature and complexity.
- Iterative reasoning & Planning – Problem-solving through multiple steps rather than a single pass.
- Self-evaluation and Reflection – Assessing the quality of outputs and making corrections when necessary.
What makes RAG Agentic?
Agentic RAG introduces autonomy and adaptability into the standard RAG pipeline by allowing the system to actively control the retrieval process rather than relying on a fixed retrieval-then-generate flow.
This means that instead of a linear pipeline, where retrieval is a single-step precursor to generation, an Agentic RAG system introduces decision points throughout the process. The system might:
- Determine whether retrieval is necessary before executing a search.
- Decide which knowledge source is most appropriate based on the query.
- Refine the retrieval process iteratively, adjusting queries or fetching additional context if needed.
- Assess the relevance of retrieved documents before using them in response generation.
These behaviors align with the agentic patterns discussed earlier, transforming RAG into a more intelligent and self-correcting process. Agentic RAG actively guides its own retrieval strategy, ensuring higher-quality and more contextually relevant answers.
Agentic Patterns for RAG
Let’s explore some of the design patterns for Agentic RAG in more detail. Each of the below patterns represents a mechanisms that allows the RAG system to make intelligent decisions at different stages of the retrieval and response generation pipeline. Throughout the diagrams, I refrain from calling the agentic nodes as actual AI Agents, given the vagueness of the definition. Nevertheless, any node where an LLM call or chain is used for a purpose other than generation, could be deemed “agentic” for the purpose of this post.
Query Analysis
Before retrieving information, an Agentic RAG system can first analyze the user’s query to determine the best approach. This includes:
- Determining if retrieval is needed at all – Some queries may already be answerable based on the model’s internal knowledge. If a query is common knowledge (e.g., “Who wrote 1984?”), an agentic system may choose to answer directly without retrieving external documents, saving computational resources.
- Selecting the best retrieval source – Instead of always querying the a single knowledge source, an agentic RAG system can intelligently route the query to the most relevant source. In our example in the limitations of traditional RAG section, our system would be able to ascertain if it should query the company’s internal policy database, or the web search API.
- Deciding the appropriate retrieval strategy – Some queries require semantic search in a vector database, while others are better suited for keyword-based or hybrid search. An agentic system can dynamically choose the best retrieval method for the query.
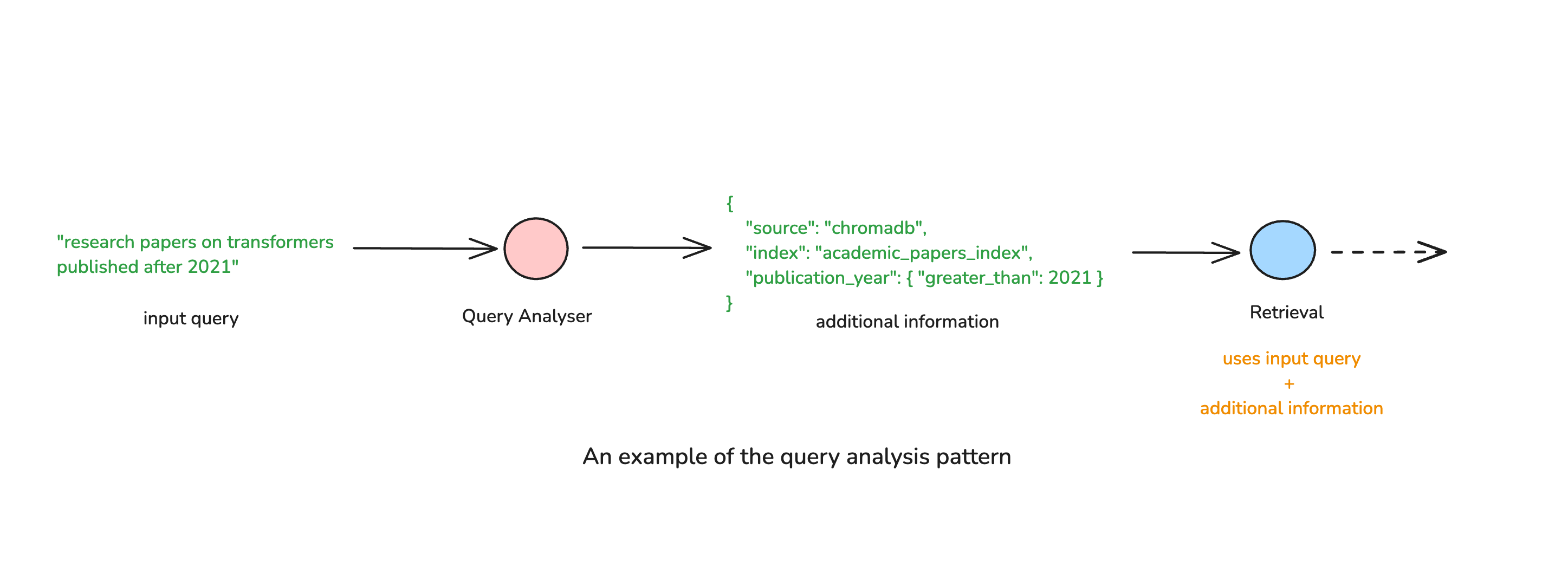
- Extracting filters – Some queries contain implicit constraints (e.g., timeframes, categories, or document types). An agentic system can automatically extract filters (e.g., “Q2 2023 financial reports on renewable energy”) and incorporate them into an appropriate structured query for the knowledge source.
Query Rewriting
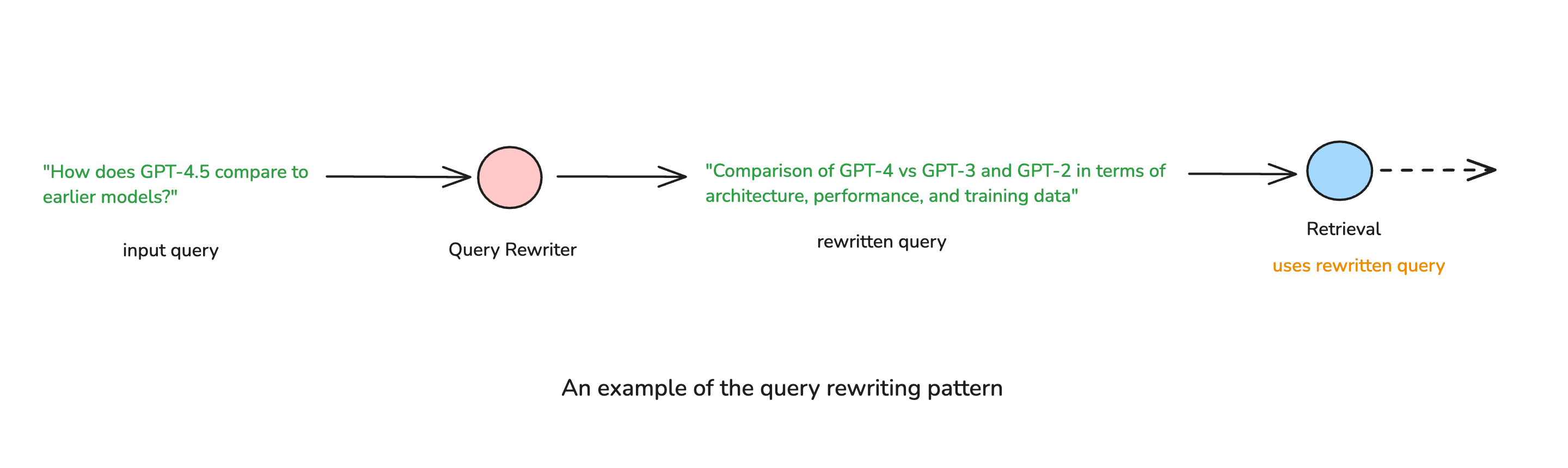
Traditional RAG systems retrieve documents based on the literal user query, which may be vague, incomplete, or poorly phrased for effective retrieval. Agentic RAG improves this by dynamically reformulating queries before retrieval, optimizing search results. Query rewriting is especially important when dealing building conversational agents. These applications often need to use the message history in order to rewrite the query to make it appropriate for further processing.
This process can involve:
- Expanding abbreviations and adding synonyms to increase retrieval coverage.
- Breaking down complex queries into smaller sub-queries to retrieve more precise information.
- Reframing queries to match the format of indexed knowledge (e.g., transforming “What are the symptoms of Type 2 diabetes?” into “Type 2 diabetes common symptoms and diagnosis”).
Planning & Multi-Step Retrieval
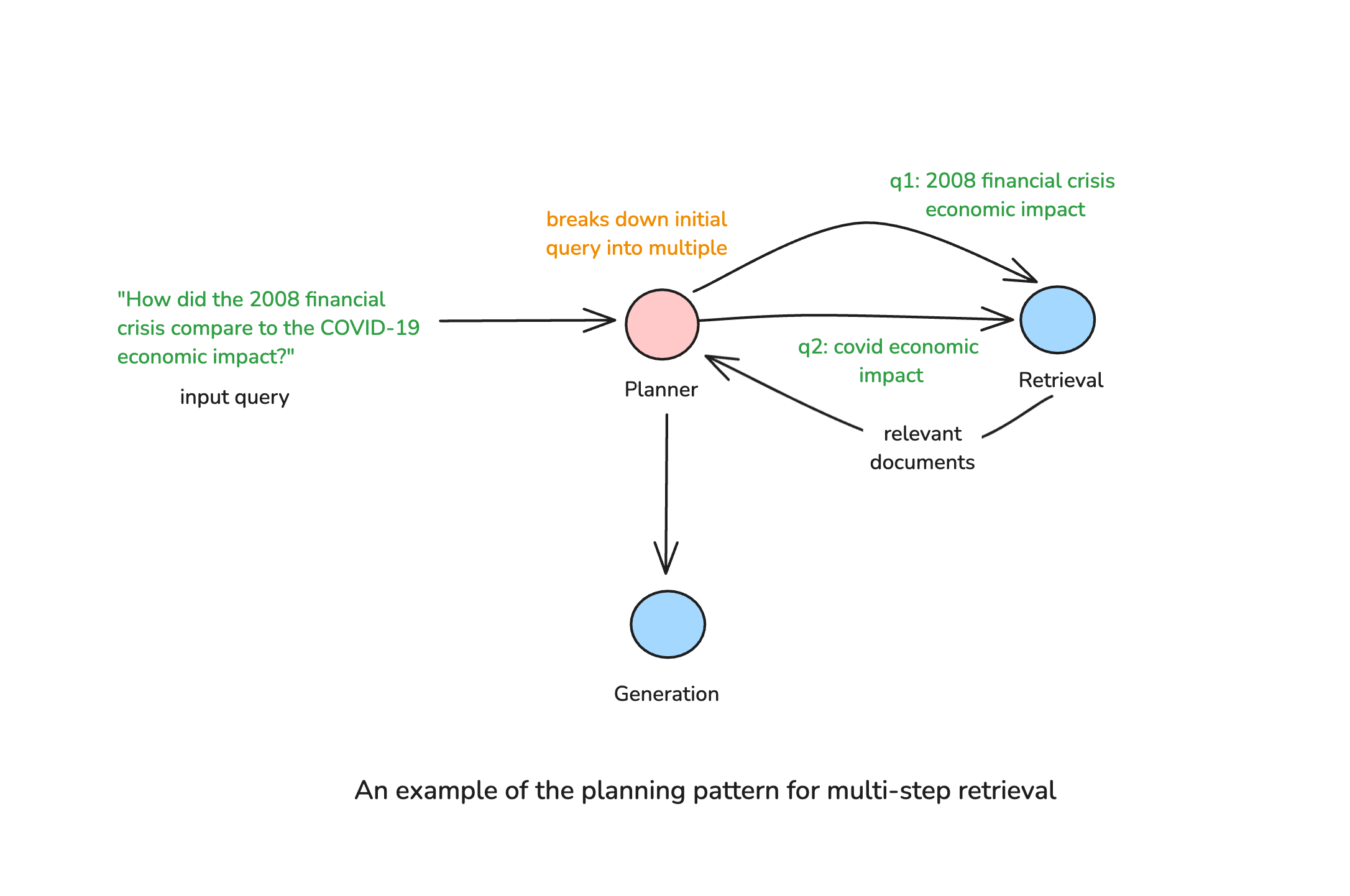
Not all queries can be answered with a single retrieval step. Complex questions often require multiple rounds of retrieval and reasoning. Agentic RAG can plan a multi-step retrieval strategy, where the system decides the sequence of actions needed to construct a complete response.
For example, given a query like “How did the 2008 financial crisis compare to the COVID-19 economic impact?”, an agentic system might:
- Retrieve data about the 2008 financial crisis.
- Retrieve data about the COVID-19 economic impact.
- Compare both retrieved sets and generate a synthesized response.
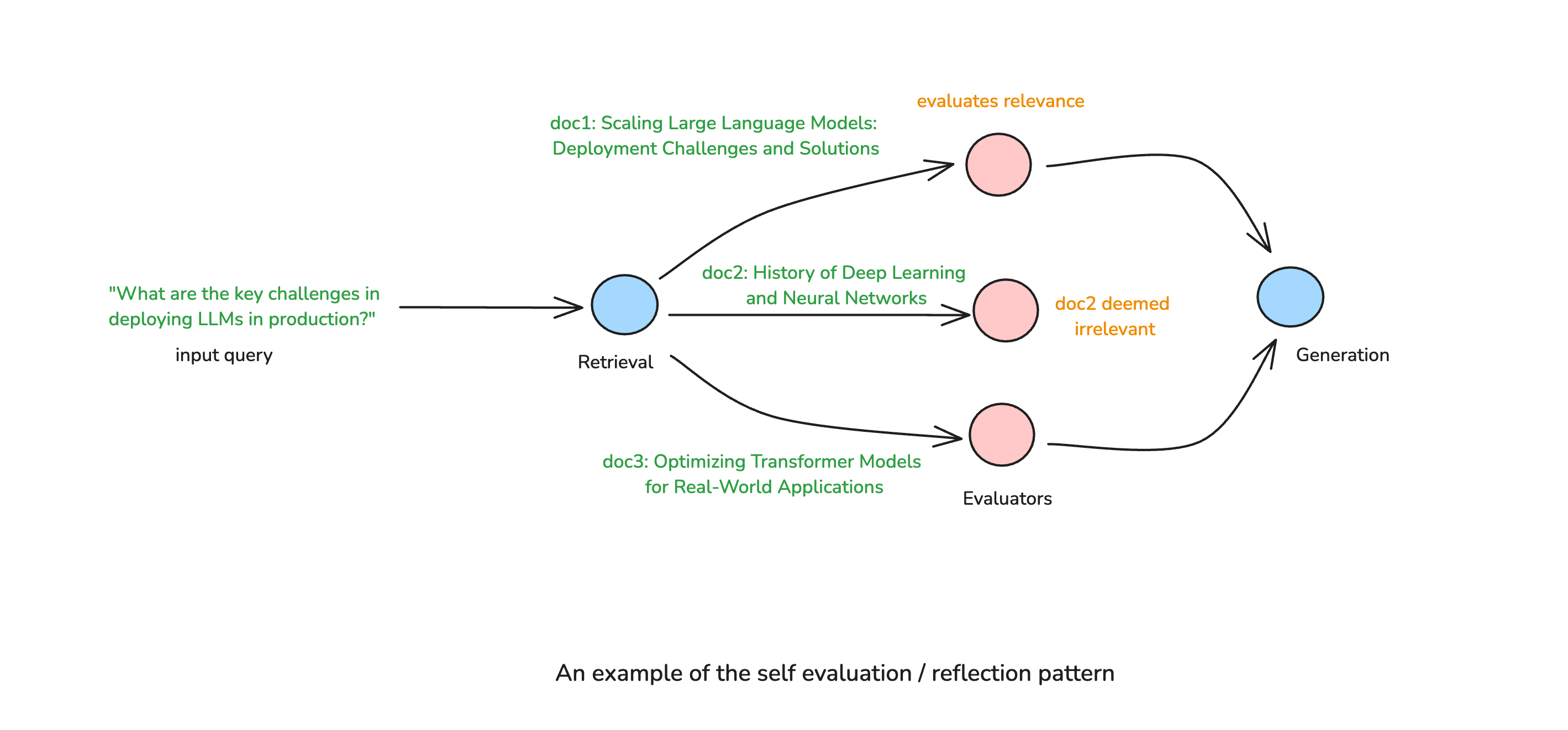
Self Evaluation through Reflection
Another limitation of traditional RAG is its inability to assess the quality of retrieved documents before using them for response generation. Agentic RAG overcomes this by incorporating self-evaluation mechanisms, where the system can actively check its own retrieval results and generated responses.
This pattern can involve:
- Grading the relevance of retrieved documents to filter out low-quality sources.
- Detecting gaps in information and re-triggering retrieval if necessary.
- Identifying contradictions between retrieved documents to improve response accuracy.
Usually, self evaluation is performed in parallel for each document being evaluated to improve both assessment quality and latency.
Bringing It All Together
The above patterns aren’t isolated. They can be combined in various ways to create sophisticated Agentic RAG architectures. It’s also common to use the same pattern at multiple points in the system to enhance its overall quality.
For example, a system might:
- Use query analysis to determine if retrieval is needed.
- Use query analysis again to extract any relevant filters from the query.
- Rewrite the query for optimal retrieval.
- Reflect on retrieved content to filter out irrelevant documents and generate a more relevant response.
This modular, adaptable approach makes Agentic RAG vastly more powerful than traditional RAG, as it can tailor retrieval strategies in real time based on the nature of the query.
In the next section, we will explore practical examples of how these patterns come together in real-world Agentic RAG pipelines.
Examples of Agentic RAG Pipelines
We will focus on three possible approaches that demonstrate how the above patterns can be applied in practice.
Single Agent Router
This is the simplest enhancement to a traditional RAG pipeline. A routing agent analyzes the query before retrieval and decides the best source of information, ensuring retrieval is both relevant and efficient.
An Example Workflow
- The router agent classifies the query based on intent.
- It dynamically selects the appropriate knowledge source (e.g., internal documents vs. web search).
- The selected retrieval process is executed, and the retrieved data is passed to the LLM for response generation.
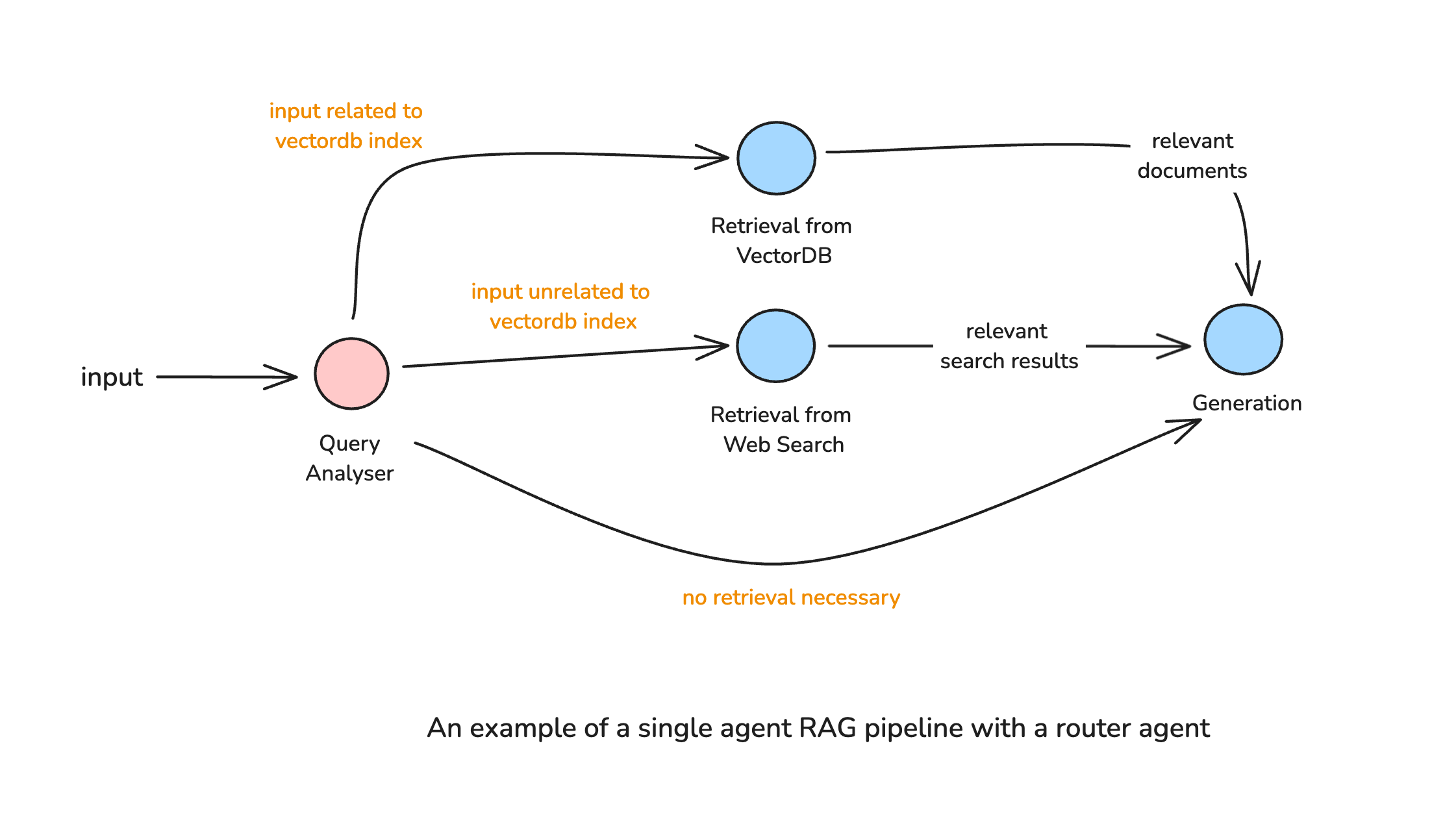
This routing-based approach introduces adaptability without adding much complexity, making it a lightweight yet impactful upgrade over standard RAG.
Corrective RAG
Corrective RAG introduces reflection mechanisms, allowing the system to refine its retrieval and response generation by reflecting the quality of the retrieval or generation steps. For example, instead of accepting retrieved documents as they were returned from the knowledge souce, the agent validates their quality, and can course correct before proceeding.
An Example Workflow
- The initial retrieval process is performed as in standard RAG.
- The agent assesses retrieved documents—checking for relevance, completeness, and contradictions.
- If needed, the agent triggers corrective actions, such as:
- Rewriting the query and performing another retrieval attempt.
- Fetching additional information from alternative sources.
- Discarding irrelevant or low-confidence documents, to reduce noise in the generation step.
- After validation and passing the necessary quality checks, does the system proceed to response generation.
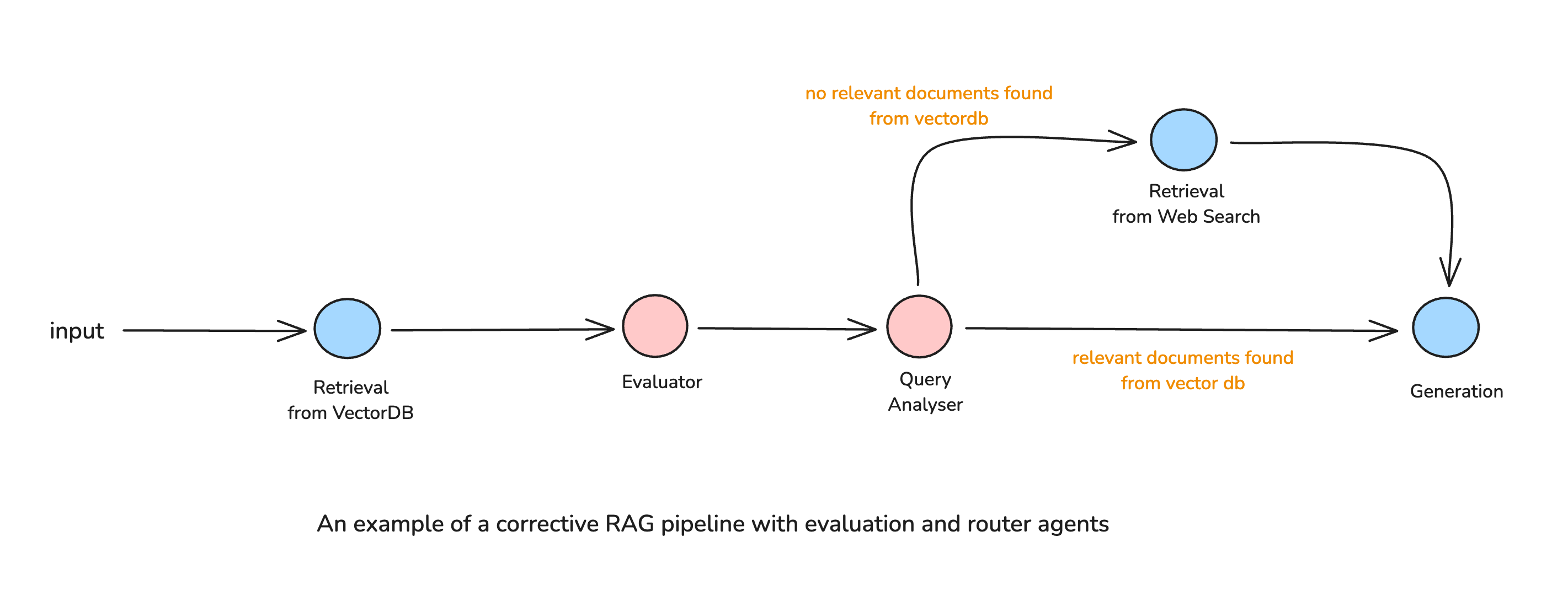
This approach transforms RAG into an iterative, self-correcting process, making it more resilient to incomplete or misleading retrievals.
I wrote a blog post on https://sajalsharma.com/posts/corrective-rag-langgraph/, which goes into detail of implementing this architecture using LangGraph.
Adaptive RAG
The Adaptive RAG pipeline leverages query analysis, retrieval refinement, and self-reflection to dynamically adjust its strategy based on the query. The workflow follows these key stages:
- Query Analysis
- The system first determines whether the query is related to the indexed knowledge base or if it requires an external search.
- If the query is relevant to the index, it proceeds with retrieval.
- If unrelated, the system routes it to an alternative method, such as a web search.
- Retrieval & Self-Assessment
- Retrieved documents are graded for relevance before proceeding.
- If documents are sufficient, they are passed to the LLM for generation.
- If they are irrelevant, the system rewrites the query and retries retrieval. Note that it is important to place a limit on the maximum number of iterations to prevent infinite retrieval loops.
- Generation & Validation
- The LLM generates an initial response based on the retrieved context.
- A validation step checks for hallucinations or incomplete answers.
- If the answer is satisfactory, it is returned.
- If not, retrieval is refined, or additional sources are queried before regenerating the response.
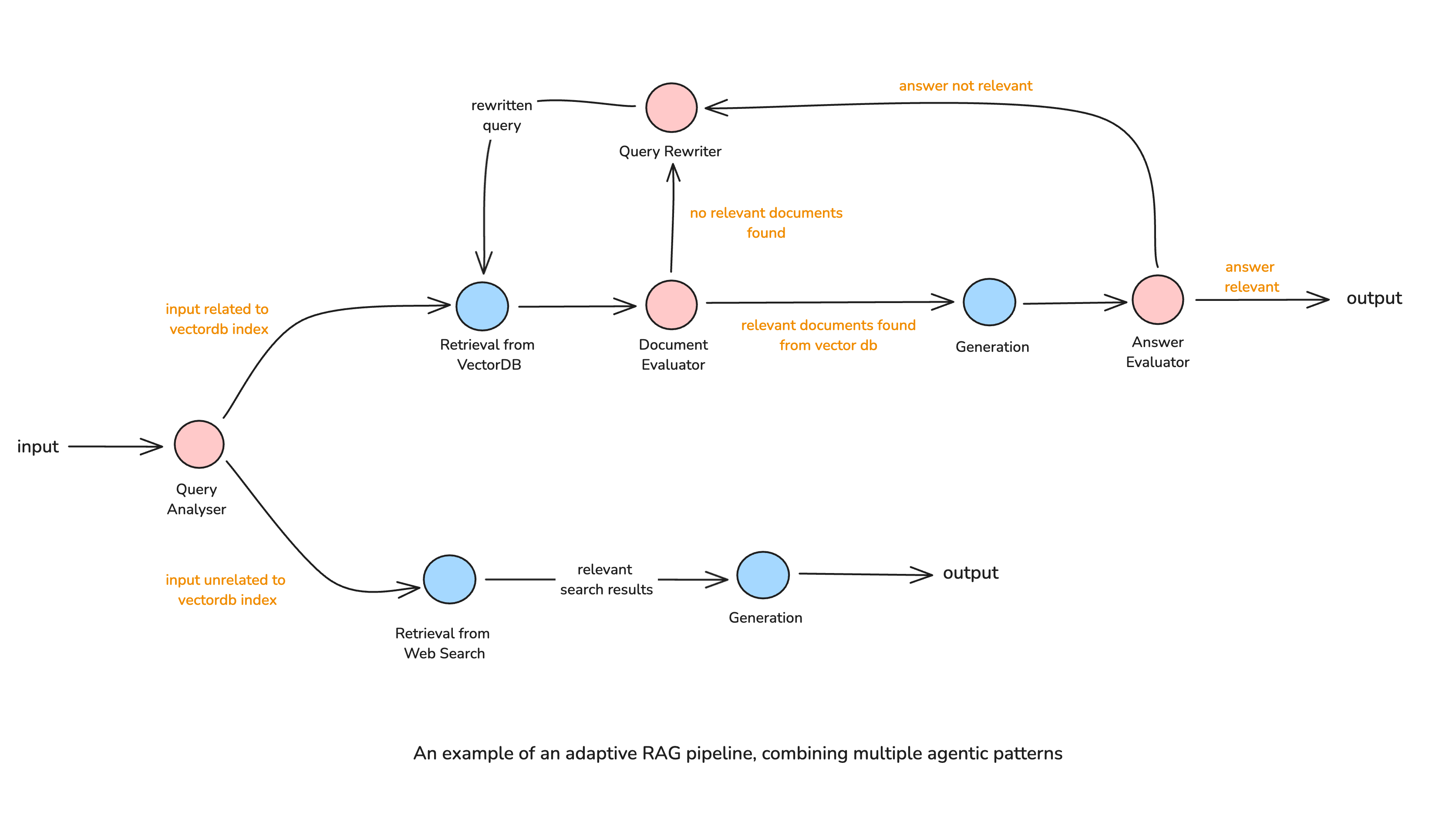
This pipeline represents the full potential of Agentic RAG, where the whole process is adaptive and responsive to query needs. Keep in mind that this workflow is just an example, and can be tailored to suit specific needs.
Challenges & Mitigation Strategies in Agentic RAG
While Agentic RAG enhances retrieval adaptability and reasoning, it also introduces several challenges that impact latency, cost, maintainability, and evaluation complexity.
1. Increased Latency Due to Multi-Step Processing
Agentic RAG dynamically refines queries, re-evaluates retrieved results, and iterates on retrieval, leading to longer response times compared to a standard RAG pipeline.
Mitigation Strategies:
- Prioritize efficiency in decision-making – Use lighter models for query routing and reflection instead of larger, flagship LLMs.
- Introduce early stopping criteria – If retrieval confidence is high after the first pass, avoid unnecessary additional retrieval steps.
- Cache intermediate results – Store frequently retrieved documents and past query responses to minimize redundant retrievals.
2. Higher Computational Costs
Additional processing, multiple retrieval steps, and self-reflection loops increase inference costs, especially when using large LLMs for decision-making.
Mitigation Strategies:
Strategies mentioned above also apply to keeping the costs under control. Additionally, we can
- Implement tiered processing – Route simple queries through a standard RAG pipeline and reserve Agentic RAG for complex queries only.
- Use cost-aware logic – Define a maximum iteration limit for refinement and retrieval loops to prevent excessive compute usage.
3. Overhead of Maintaining Prompts for Decision Points
Agentic RAG systems rely on LLMs making decisions at multiple stages, such as query classification, retrieval re-ranking, and response validation. Crafting and fine-tuning prompts for these decision points requires ongoing maintenance.
Mitigation Strategies:
- Use modular prompt templates & prompt libraries – Instead of hardcoding separate prompts for each agent, use a consistent structure across all decision-making steps. Take advantage of prompt management tools such as Langtrace.
- Limit decision-making complexity – Not every step needs an LLM decision—use rule-based heuristics for simple routing tasks to reduce reliance on prompts.
4. Complexity of Evaluation
Traditional RAG evaluation methods focus on retrieval accuracy, but Agentic RAG requires evaluating decision-making quality, retrieval effectiveness, planning & reflection accuracy, and final response correctness, making the evaluation process more complex.
Mitigation Strategies:
- Break evaluation into stages – Measure the quality of each agent / decision point separately. For example, measure retrieval quality separately from the accuracy of query analyser and the reflection agents.
- Use automatic evaluation pipelines – Implement LLM-based grading or embedding similarity scoring to automate quality assessments, as much as possible.
Conclusion
Agentic RAG represents a significant evolution in retrieval-augmented generation, introducing autonomy, reasoning, and adaptability to improve how AI retrieves and generates information. By moving beyond a fixed retrieve-then-generate pipeline, Agentic RAG enables dynamic decision-making—choosing the best data source, refining queries, iterating on retrieval, and self-evaluating responses before finalizing an answer. This adaptability allows it to handle complex queries, ensure information remains up-to-date, and improve response quality through reflection and correction.
However, introducing agentic behavior comes with trade-offs. Additional decision points increase latency and computational costs, and maintaining prompts, retrieval strategies, and evaluation pipelines requires ongoing refinement. Despite this complexity, for applications where accuracy, reliability, and adaptability are critical, the benefits outweigh the challenges. By shifting from a passive retriever to an active reasoning system, Agentic RAG makes AI-powered retrieval more robust, context-aware, and verifiable, paving the way for more advanced, real-world-ready knowledge systems.
Further Reading
- Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei. (2025). Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
- Agentic RAG with Qdrant