Table of contents
Open Table of contents
Introduction
The emergence of Large Language Models (LLMs) like OpenAI’s GPT-4 and Anthropic’s Claude has triggered an explosion of products built on these foundation models. In just the past two years, we’ve witnessed hundreds of new companies launching with products that leverage LLMs for everything from marketing to code generation, customer support to creative collaboration. While AI-powered products aren’t new, they’ve become dramatically easier to build and more powerful with the advent of LLMs. Tasks that once required complex machine learning pipelines can now be accomplished with a well-crafted prompt and an API call.
I find this democratization of AI capabilities exhilarating, opening up new possibilities both for a new class of products, and for interesting features for the existing class. Though I can’t help but notice the concerned expressions on investors’ faces as they consider the implications. After all, if anyone with technical skills can quickly build AI products, what creates lasting value and defensibility in this new landscape? In short, “What’s the moat?”. In my experience working at Menyala, a Venture Studio, I’ve been on the front lines of answering this question quite often. For each AI project I’ve worked on, from in house AI-powered venture analysis to domain specialised search engines, two questions often dominate conversations:
- “What happens if OpenAI decides to build this themselves?”
- “AI applications are just an API call to OpenAI. Whats’s the moat?”
I’ve explained my thoughts on this topic countless times. But, the recurring nature of these discussions revealed a need for a structured write-up on this topic. In this post, I outline my thoughts on the matter, and why, in my opinion, moat for AI applications is similar to that for other applications.
First, What’s a Moat?
 The AI Moat Wars, by GPT-4o. Prompt: cartoon image of two robot factions, one on top of a roof of a castle and one outside, fighting with lasers, separated by a moat.
The AI Moat Wars, by GPT-4o. Prompt: cartoon image of two robot factions, one on top of a roof of a castle and one outside, fighting with lasers, separated by a moat.
The term “economic moat,” popularized by Warren Buffett, refers to a company’s ability to maintain competitive advantages over its rivals, protecting its long-term profits and market share. Just as a medieval castle used water-filled moats to keep invaders at bay, businesses need defenses against competitors who might replicate their success or erode their margins.
Historically, economic moats have come from various sources: geographical advantages for retailers, patent protection for pharmaceutical companies, brand loyalty for consumer goods, or regulatory barriers in industries like telecommunications.
Moats in Tech Businesses
In technology, moats take on different characteristics than in traditional industries. While a restaurant might rely on location or a manufacturer on patents, tech companies often build moats through network effects, switching costs, or proprietary technology.
Tech products and services face unique challenges:
- They can be replicated more easily than physical goods
- They have near-zero marginal cost of distribution
- They often operate in rapidly evolving markets
- Innovation cycles are compressed, with advantages quickly neutralized
For startups building on foundation models like OpenAI’s GPT, this challenge is even more pronounced. When your core technology is available to anyone with an API key and a credit card, traditional technical advantages may look minimal.
When analyzing defensibility, I find it helpful to separate moats into two broad categories, technology moats, tied to the core technology and business moats, tied to the business built on top of the technology.
Examples of Technology Moats:
- Proprietary algorithms or models that competitors cannot easily reproduce
- Unique data sets that improve over time through usage (data network effects)
- Technical integrations that create high switching costs
- Infrastructure optimizations that provide cost or performance advantages
- Patents and intellectual property that prevent direct replication
- Custom fine-tuning or training techniques that improve model performance
Examples of Business Moats:
- Network effects where each additional user increases value for all users
- Marketplace dynamics that become more valuable with scale
- Switching costs that make it painful for customers to move to alternatives (notice that this is separate from similar switching costs of technology).
- Scale economies that reduce costs as the business grows
- Brand and reputation that engender trust and loyalty
- Distribution channels that efficiently reach target customers
- Regulatory advantages or compliance capabilities in regulated industries
For LLM applications, both types of moats matter—but as we’ll see the most successful AI startups typically combine elements of both, creating multiple layers of defensibility.
Finding the Moat in GPT Wrappers
Commoditization of Foundation Models
Foundation models are rapidly becoming commodities. What was groundbreaking in 2022 is increasingly standard in 2025. We’re witnessing an intense battle among technology giants and some well-funded startups, all competing for foundation model supremacy. OpenAI, Anthropic, Google (with Gemini), Cohere, Meta, Mistral AI, and newcomers like DeepSeek are engaged in a relentless race to develop more capable models.
This competition is multi-dimensional. Companies aren’t just fighting on benchmark metrics, but also on specialized capabilities, multimodal features, context length, inference speed, and pricing. The pace is staggering—what was state-of-the-art six months ago is now merely adequate. Meanwhile, open-source models from Meta and Deepseek continue to narrow the gap with commercial offerings. These models can be deployed privately, fine-tuned for specific use cases, and modified without the constraints of API-only access.
So let’s ask a different question: What’s OpenAI’s moat? While they currently lead in many capabilities, their advantage is constantly under pressure from these well-funded competitors fighting on multiple fronts. Even OpenAI recognizes this vulnerability, which explains their aggressive push into end-user applications (ChatGPT, DALL-E, Voice Mode) rather than relying solely on API revenue.
These companies understand that model capabilities alone provide temporary advantages at best. The technology is advancing too rapidly, with too many brilliant researchers and engineers focused on the same problems. When one company discovers a breakthrough, others quickly follow or find alternative approaches. This constant advancement is great for the industry overall but means that relying on the underlying LLM alone for defensibility is a precarious strategy. If the foundation model providers themselves are racing to build applications, that should tell you something about where the defensible value lies.
The Importance of the Application Layer
I like to think of LLMs as another paradigm of programming. Just as JavaScript provides a language for web development and React offers a framework for building interfaces, LLMs new possibilities for creating intelligent applications. The foundation model isn’t the product—it’s what you build with it that matters. ChatGPT is an application layer product, powered by the GPT foundational models, that extends the foundational model with capabilities such as memory, research, web search, and more.
The application layer requires considerable work. At its core, the infrastructure needed for production LLM applications is substantial and nuanced. At the very least, developers need to build robust prompt engineering and management systems that maintain consistency across user interactions. Often, they must implement retrieval-augmented generation (RAG) architectures that connect models to private data, allowing their AI products access to domain-specific information rather than generic knowledge. This often involves custom vector databases, embedding strategies, and retrieval mechanisms that become increasingly sophisticated as applications scale.
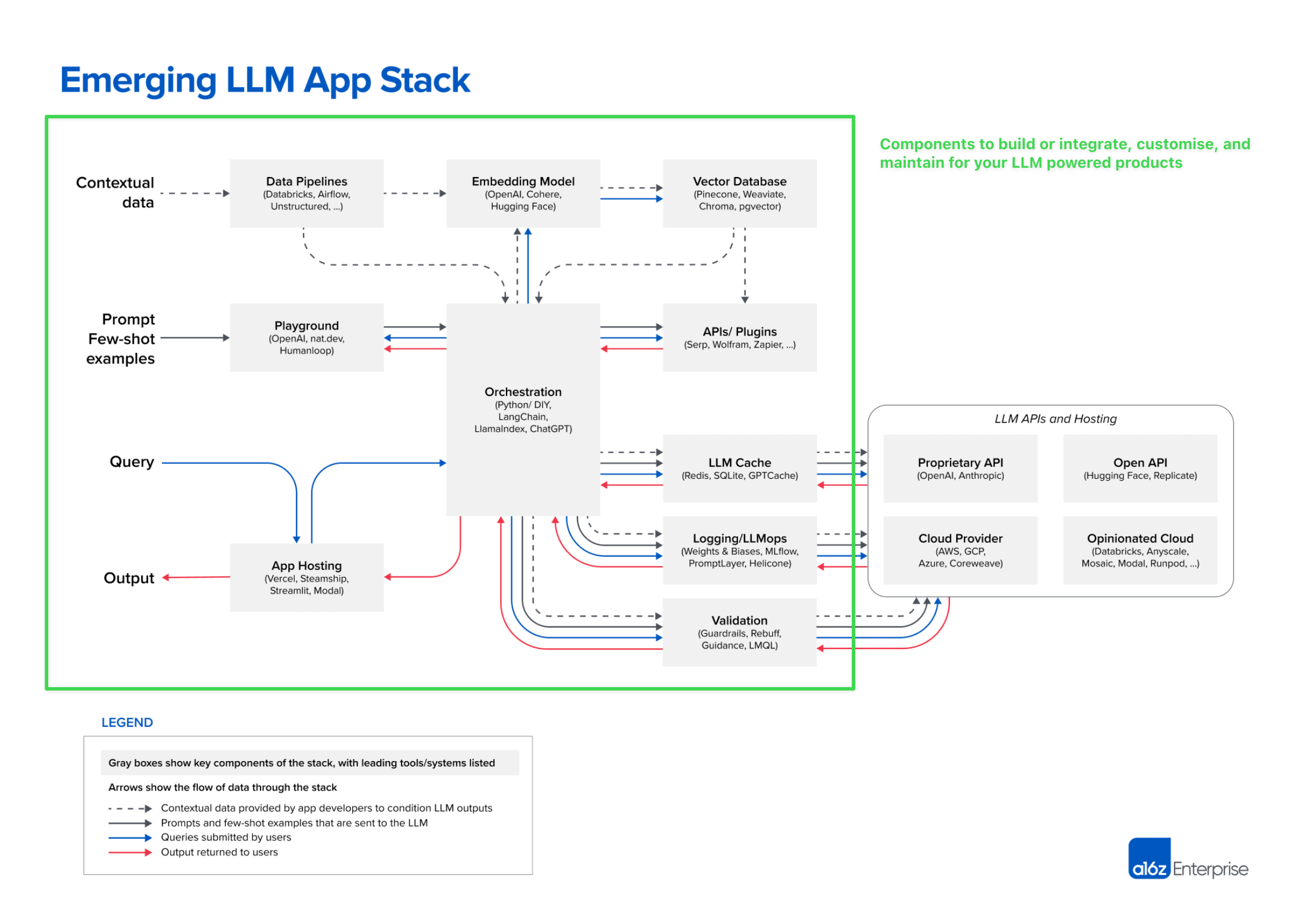 a16z’s “Emerging LLM App Stack” offers a high level overview of the components needed for production LLM applications. Image Source: a16z
a16z’s “Emerging LLM App Stack” offers a high level overview of the components needed for production LLM applications. Image Source: a16z
*Sidebar on RAG: RAG is HARD. The retrieval component of RAG is particularly critical and often underestimated - it’s not merely a simple search function but rather a complex ranking challenge that combines semantic relevance, contextual appropriateness, and business logic. Building effective retrieval systems requires expertise in information retrieval theory, vector similarity algorithms, hybrid search approaches, and dynamic re-ranking techniques. The most sophisticated RAG implementations employ multi-stage retrieval pipelines with filtering, chunking strategies optimized for specific content types, and context-aware relevance scoring.
As applications scale to millions of documents or specialized domains, these retrieval capabilities often become a significant competitive advantage - one that’s far more difficult to replicate than the surface-level integration with foundation models that users actually see.*
If you decide that RAG is not enough, due to accuracy, latency or security constraints, then you may turn to fine-tuning a foundation model. Fine-tuning pipelines add another layer of complexity, requiring specialized datasets, evaluation protocols, and model management workflows. Developer teams need to carefully balance performance gains against the costs of customization.
Beyond these technical aspects, production systems need comprehensive monitoring, evaluation frameworks to catch errors, and security controls to protect sensitive information—all critical components that casual API integrations typically lack.
The user experience layer is equally important in creating defensible products. Effective LLM applications need thoughtfully designed interfaces that make AI capabilities accessible to non-technical users. My personal favourite example is how Cursor, the IDE built on a fork of VSCode, brought the code writing capabilities of LLMs to where a developer spends most of their time, raising millions. User feedback loops that improve performance over time create both better products and data assets that competitors cannot easily replicate.
Domain specialization represents perhaps the most underestimated aspect of LLM applications. Successful products embed deep industry-specific knowledge into every level of their architecture—from prompt design to evaluations. Custom data sources provide relevant context that generic models lack, while specialized evaluation metrics ensure outputs meet the exact standards of particular industries. Adapting language and terminology to specific verticals makes interactions feel natural to professionals, while building compliance with industry regulations directly into the product creates both value and barriers to entry. Workflows designed for particular professional contexts solve real problems rather than showcasing raw AI capabilities.
Beyond the technical aspects, non-technical elements often determine which AI applications succeed in the market. Strategic partnerships with key industry players can provide both distribution advantages and domain knowledge. Efficient distribution channels help products reach target users before competitors can gain traction. Customer success programs ensure adoption and retention, particularly important for novel AI tools where users may need guidance to realize full value. Thoughtful product positioning differentiates specialized tools from general-purpose alternatives, while pricing models aligned with value creation ensure sustainable businesses.
Creating a complete product that delivers consistent value requires expertise across multiple disciplines and significant investment in the layers surrounding the model. The most defensible AI products combine all these elements into cohesive experiences that solve specific problems better than general-purpose alternatives. They embed domain knowledge, workflow understanding, and user insights in ways that can’t be easily replicated simply by accessing the same foundation model.
Case Studies of AI Startups Seeking Moat
Perplexity
Perplexity has built a powerful AI search engine despite competing directly with Google, one of the world’s most valuable companies with decades of search expertise. On paper, this should be an impossible battle, yet Perplexity has gained millions of users and raised significant funding at a multi-billion dollar valuation.
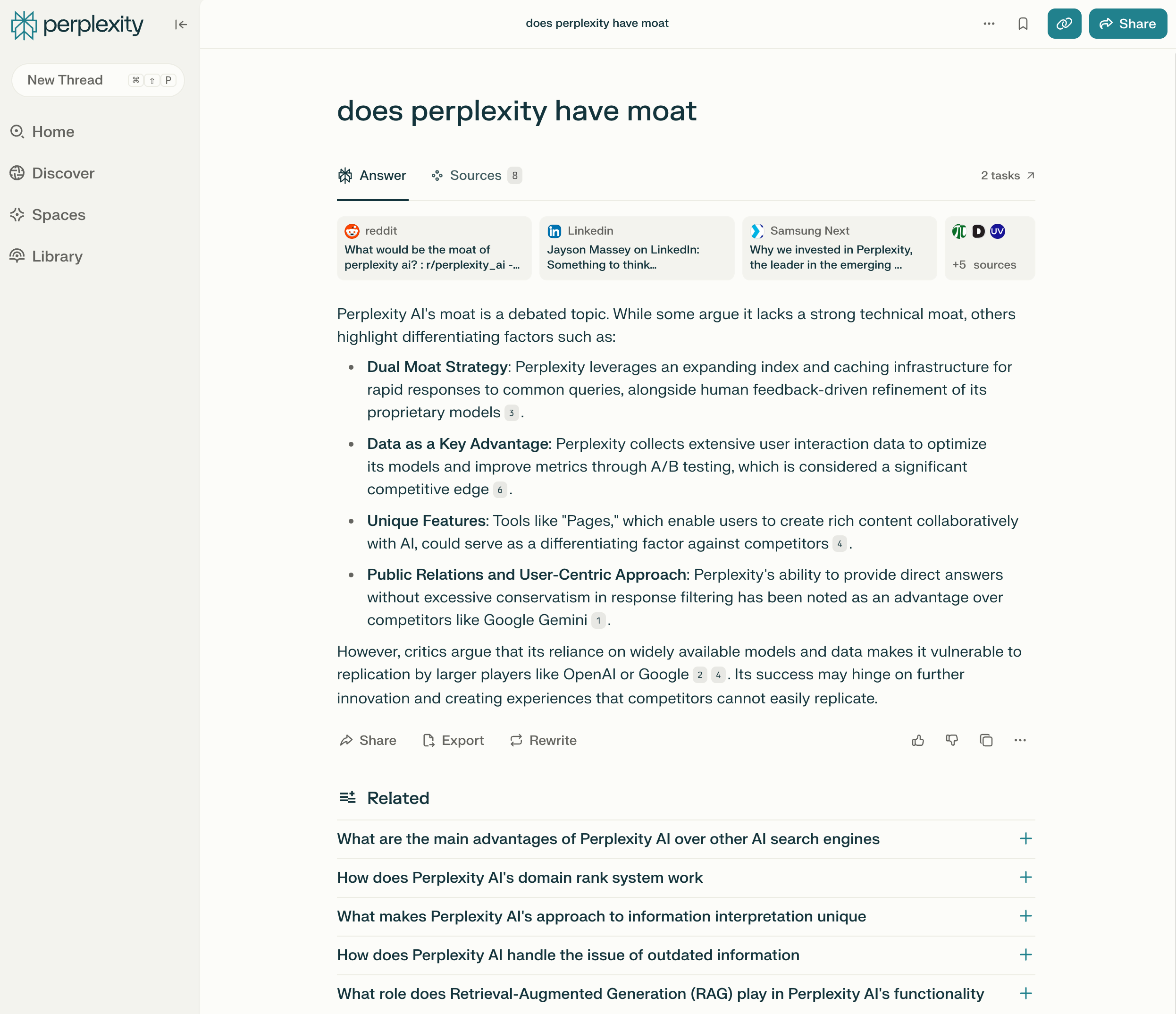 Perplexity’s thoughts on Perplexity’s moat.
Perplexity’s thoughts on Perplexity’s moat.
Their moat includes several reinforcing elements:
- User Experience: Perplexity created a conversation-first interface that feels more natural than traditional search. Rather than returning ten blue links, it provides direct answers in a conversational format that builds on previous questions.
- Speed and Relevance: Their system optimizes for quick, accurate answers rather than SEO-optimized results. Their specialized infrastructure combines web search, RAG techniques, and custom prompting to generate coherent, contextual responses.
- Business Model Innovation: Rather than relying exclusively on advertising (Google’s model), Perplexity offers subscription offerings that focus on premium features like deeper research, higher query limits, and specialized tools. This alignment of incentives means they’re optimizing for user value rather than advertiser clicks.
- Focus on Research Use Cases: By targeting users with specific information needs beyond simple queries, Perplexity has carved out a niche that values depth over breadth. Their Pro features emphasize comprehensive research capabilities that traditional search engines don’t prioritize.
Perplexity was among the first to effectively combine web search with LLM capabilities at scale, giving them important first-mover advantages. This early lead has created a powerful data flywheel—as users conduct searches, Perplexity captures valuable feedback and query patterns to fine-tune their models specifically for information retrieval tasks. They’re leveraging this data advantage to develop custom models optimized for search rather than relying solely on general-purpose LLMs. While it’s too early to declare a clear winner in the AI search race—Google has responded with its own AI Overview feature, and OpenAI offers similar capabilities through ChatGPT with browsing—Perplexity’s continued growth and resilience are remarkable. The fact that a startup launched in 2022 can stand toe-to-toe with tech giants in such a fundamental category speaks volumes about the opportunity for reinvention that LLMs have created. Even if Perplexity doesn’t ultimately dominate search, they’ve proven that well-executed AI applications can challenge seemingly unassailable incumbents by reimagining core user experiences rather than merely iterating on existing paradigms.
CharacterAI
CharacterAI created a platform for conversational AI characters that users can interact with or create themselves. It’s a product that attracts millions of users despite competition from both established players and new entrants.
 Reliving my high school nightmares through CharacterAI.
Reliving my high school nightmares through CharacterAI.
Their defensibility comes from multiple sources:
- Network Effects: CharacterAI has fostered a powerful user-generated content flywheel. Users create AI characters ranging from historical figures to original personas, which attract more users, who in turn create more characters. This library of characters—over 16 million by recent counts—creates a content ecosystem that becomes more valuable with each addition.
- Community: The platform has cultivated a passionate user base that continues creating, sharing, and improving characters. Active forums, social media groups, and community events strengthen the bonds between users and the platform. This community isn’t just using the product; they’re co-creating it.
- Technical Expertise: Founded by former Google researchers with deep experience in conversational AI, CharacterAI has built proprietary technology optimized specifically for maintaining consistent character personas over extended conversations. This specialization produces interactions that feel more coherent and engaging than generic chatbots.
- Targeted Use Case: Rather than trying to build a general-purpose assistant like ChatGPT, CharacterAI focused specifically on entertainment, companionship, and creative expression. This clear focus allowed them to optimize every aspect of the experience for these specific use cases.
- Young User Base: CharacterAI has become particularly popular with Gen Z users, establishing strong brand recognition with a demographic that will have increasing purchasing power over time. This young user base also provides cultural relevance and word-of-mouth growth that’s difficult for corporate alternatives to replicate.
When I visited my younger cousins last year, they were deep into CharacterAI. Like, they weren’t just messing around—they were spending hours every day talking to their favorite characters. They knew exactly which characters were good, which ones stayed in character, and which ones were mid. That day, they were on it for over six hours straight and wouldn’t stop bugging their dad to buy them credits. Meanwhile, I asked if they’d tried ChatGPT and they looked at me like I wasn’t with the times. “Why would we use that?” one of them said. “It’s not fun.”
While OpenAI’s GPT marketplace enables custom assistants, CharacterAI maintains its dominance in the entertainment and roleplay niche. The company’s future became more complex when Google hired back Character AI’s founding leadership while entering a non-exclusive licensing agreement for the underlying technology—suggesting both the tremendous value of their innovations
Midjourney
Midjourney has remained competitive in AI image generation despite powerful alternatives from OpenAI (DALL-E), Stability AI, and others. In a field where the underlying technology is rapidly evolving and becoming more accessible, Midjourney has maintained a loyal user base and sustainable business model.
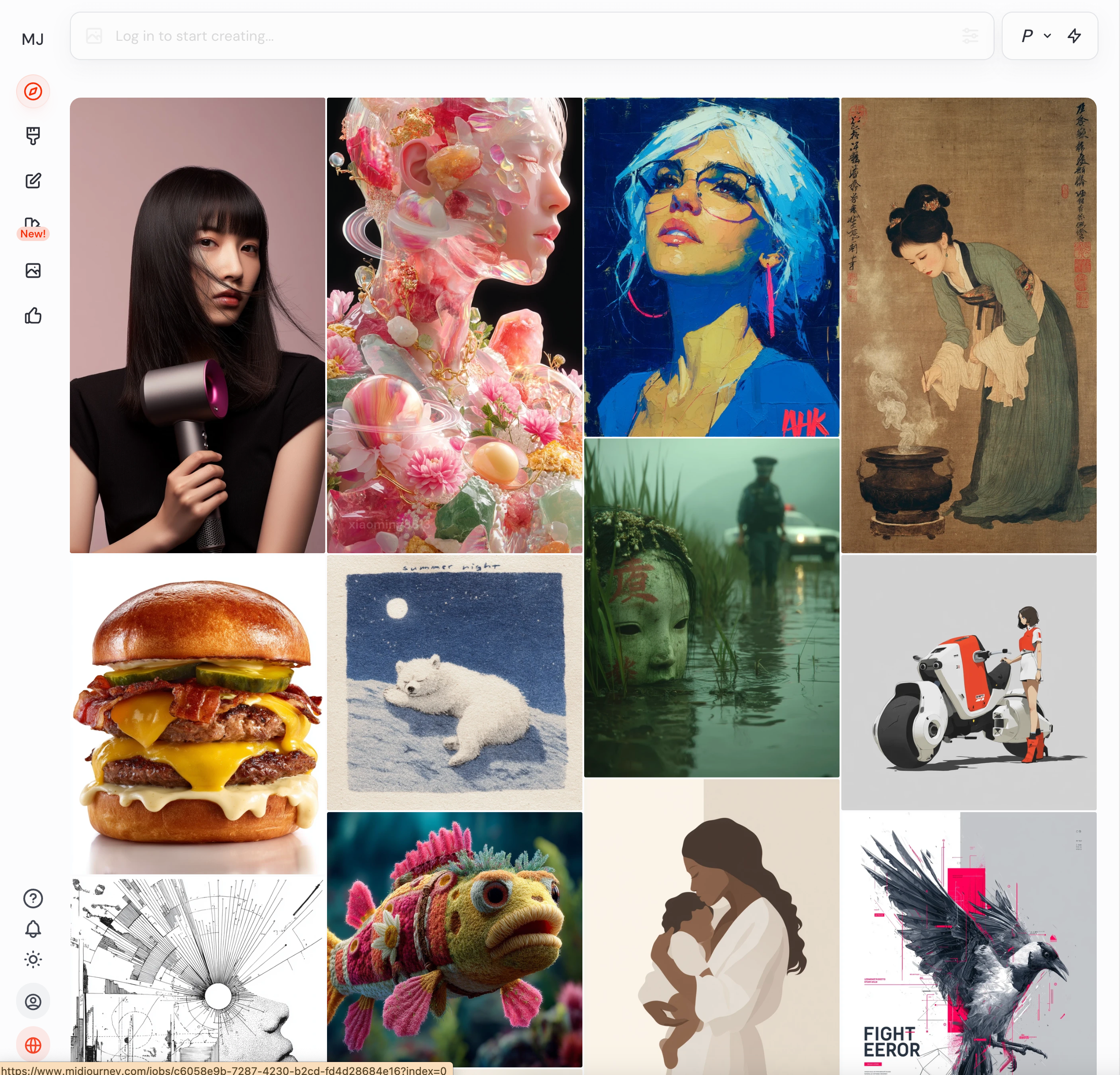 Midjourney’s image board, as shown in the screenshot, offers a powerful blend of visual discovery and prompt transparency that fuels creative exploration in a way that’s both intuitive and inspiring.
Midjourney’s image board, as shown in the screenshot, offers a powerful blend of visual discovery and prompt transparency that fuels creative exploration in a way that’s both intuitive and inspiring.
Their defensibility stems from several sources:
- Aesthetic Differentiation: Midjourney developed a distinctive visual style that many users specifically seek out.
- Community-Centered Approach: Their Discord-based interface created a strong user community where people share prompts, techniques, and results. This community became a key part of the product experience, fostering learning and creative inspiration that extends beyond the generator itself.
- Iterative Improvement Cycle: Midjourney established a rapid feedback loop with users, incorporating suggestions and refining their model based on community input. This responsive development built loyalty and continuously improved the product in ways aligned with user desires.
- Simple Interface: While competitors added complex options and parameters, Midjourney maintained a relatively simple interface that prioritizes accessibility. This focus on ease of use rather than technical complexity allowed them to reach creative professionals who aren’t technical experts.
- Clear Business Model: Midjourney implemented a straightforward subscription model from early on, creating a sustainable revenue stream without the uncertainty of tokens or credits. This clarity helped establish a healthy business while some competitors struggled with monetization.
Midjourney’s success shows how even in a crowded market with rapidly evolving technology, focusing on a specific aspect of the user experience and building community can create lasting value. They didn’t need to have the most technically advanced model to build a defensible business.
A Note on Non-AI Based David vs Goliath Tech Battles
Similar patterns appear in other technology markets where startups have successfully competed against dominant incumbents:
Calendly vs Google Calendar: Despite Google Calendar’s ubiquity, Calendly thrived by solving the specific problem of scheduling across organizations with a purpose-built interface. Google Calendar offered basic appointment slots, but Calendly created a complete scheduling experience with customization, integrations, and team features. By 2024, Calendly had over 20 million users and continued growing despite Google’s dominance in the broader calendar space.
Calendly didn’t try to replace Google Calendar—it complemented it by focusing on a specific pain point that the general-purpose tool didn’t address well.
Superhuman vs Gmail: Superhuman built a premium email experience on top of Gmail’s infrastructure, proving that users will pay for superior experience even when free alternatives exist. They focused obsessively on speed, keyboard shortcuts, and productivity features for power users. Despite Gmail’s billion-plus users and constant improvements, Superhuman maintained a loyal user base willing to pay $30/month for a better experience.
Even platform-level applications like email can be improved upon when you focus intensely on specific user needs and experiences rather than trying to serve everyone.
Notion vs Microsoft Office: Notion competed successfully against Microsoft’s dominant Office suite by reimagining knowledge management for modern teams. Rather than creating marginally better versions of Word or Excel, they built a flexible workspace that combined documents, databases, and wikis in a unified interface. This approach resonated with startups and creative teams who valued flexibility over the structure of traditional office tools.
Rethinking category assumptions rather than competing on incremental improvements can create openings even against entrenched incumbents.
These examples demonstrate that application layer innovation can create defensible businesses even when building on commoditized infrastructure or competing against dominant platforms.
Conclusion
The democratization of AI through foundation models has lowered barriers to entry, but it hasn’t eliminated the need for defensibility. Rather, it has shifted where defensibility comes from. The pattern resembles other technological transitions: as lower layers of the stack become commoditized, value moves up to the application layer and adjacent capabilities.
In the age of LLM applications, moats are built through:
- Specialization: Deep understanding of specific domains and use cases creates products that solve real problems better than general-purpose tools. The more specific your focus, the more difficult it becomes for horizontal platforms to compete effectively.
- Integration: Seamless connection with existing workflows and systems reduces friction and increases switching costs. When your product becomes embedded in daily operations, replacing it becomes increasingly difficult, even if alternatives offer marginally better features.
- Data Advantage: Proprietary data for training, fine-tuning, or retrieval creates results that cannot be easily replicated. Whether through user-generated content, exclusive partnerships, or accumulated usage data, unique information assets become increasingly valuable over time.
- User Experience: Interfaces designed for specific contexts and needs can dramatically outperform general solutions in efficiency and satisfaction. The cumulative effect of hundreds of user-centered design decisions creates products that feel “just right” for their intended audience.
- Distribution: Channels to reach and retain customers become more valuable as customer acquisition costs rise. Established relationships, reputation in a vertical, and efficient marketing systems all contribute to sustainable growth in competitive markets.
- Execution: The ability to build reliable, scalable systems that consistently deliver value is itself a competitive advantage. Technical excellence in AI operations, security, and performance optimization creates a gap that competitors must invest heavily to close.
- Ecosystem: Building complementary tools, integrations, and community around your core product increases its overall value and creates additional switching costs. The network effects of an ecosystem can provide protection even against well-resourced competitors.
The most successful AI products will be those that solve real problems for specific users in ways that are difficult to replicate.
Are you addressing the critical “last mile” challenges that incumbents overlook because they’re too focused on general-purpose capabilities? Is your “wrapper” supported by the right operational capabilities—rigorous evaluation frameworks, domain-specific guardrails, and purpose-built interfaces that transform raw AI capabilities into polished, trustworthy solutions?
In my opinion, this dynamic isn’t novel. Incumbents and competitors inevitably battle for the same market segments, with AI representing merely another technological paradigm. The truly defensible products combine deep domain understanding with operational excellence, creating experiences that feel magical not because they leverage the latest model, but because they meticulously craft every aspect of the user journey. In this evolving landscape, the companies that thrive won’t simply provide access to AI—they’ll solve complete problems through a seamless integration of technology, domain expertise, and unwavering attention to the details that matter most to their specific users.
Watch out for my next post in this topic, where I answer some of the most frequently asked questions about moats in the age of AI, such as “What if OpenAI builds this?”, and “Building AI applications is so easy, anyone can do this.”