Table of contents
Open Table of contents
Introduction
Note: This post focuses on the conceptual architecture and practical implications of MCP rather than implementation details. If you’re looking for code examples and step-by-step implementation guides, stay tuned for an upcoming deep dive into building MCP servers and clients.
What’s an MCP?
You’ve probably come across this analogy: “MCP is like USB-C for AI.”
While it sounds intuitive at first, I find it a bit reductive. It made my engineering brain do a double take: “Wait, what exactly does that mean?”
The analogy works from a marketing perspective, but we need to understand the deeper technical implications and architectural patterns that make this comparison meaningful. And so began a journey to make sense of MCP and why exactly it is like USB-C for the AI ecosystem.
The Model Context Protocol (MCP) is an open standard that defines a uniform way for AI models (especially LLMs) to access external data and tools. At its core, MCP solves the fundamental challenge of AI isolation - the reality that even the most sophisticated models are severely limited by their separation from real-world tools and data sources. Just as USB-C created a universal interface that eliminated the chaos of proprietary connectors, MCP creates a standardized protocol that eliminates the fragmented landscape of AI-to-tool integrations.
This standardization unlocks some truly awesome capabilities that were previously either impossible or prohibitively complex to implement. But to understand why MCP represents such a paradigm shift, we first need to examine the fragmented world that existed before it - and why the old approaches simply couldn’t scale.
A World Without MCPs - The MxN Problem
Tool Use / Function Calling
Before MCP existed, shipping an LLM-based AI product connected to external systems (hereby known as tools) meant wiring these up through something known as function calling. The process worked by declaring a JSON schema for each operation and passing it to an LLM invocation. If the LLM returned a function_call in the response along with parameters to execute the call, our backend system could execute it, get a result, and glue it back to a subsequent LLM invocation.
This approach worked fine for simple use cases, but it came with significant limitations. Different LLMs spoke different dialects - OpenAI used one schema format, Anthropic used another, and Google’s Gemini had its own variations. This meant duplicating schemas and orchestration code for each LLM provider. Tools and their capabilities were discovered statically by the LLM since we passed them in each invocation, creating a rigid, compile-time dependency structure.
As products grew in scope - whether building multiple features within a single product or developing different products entirely - this approach quickly became unwieldy, leading to what’s known as the M×N integration problem: connecting M AI applications with N external tools required M×N custom integrations.
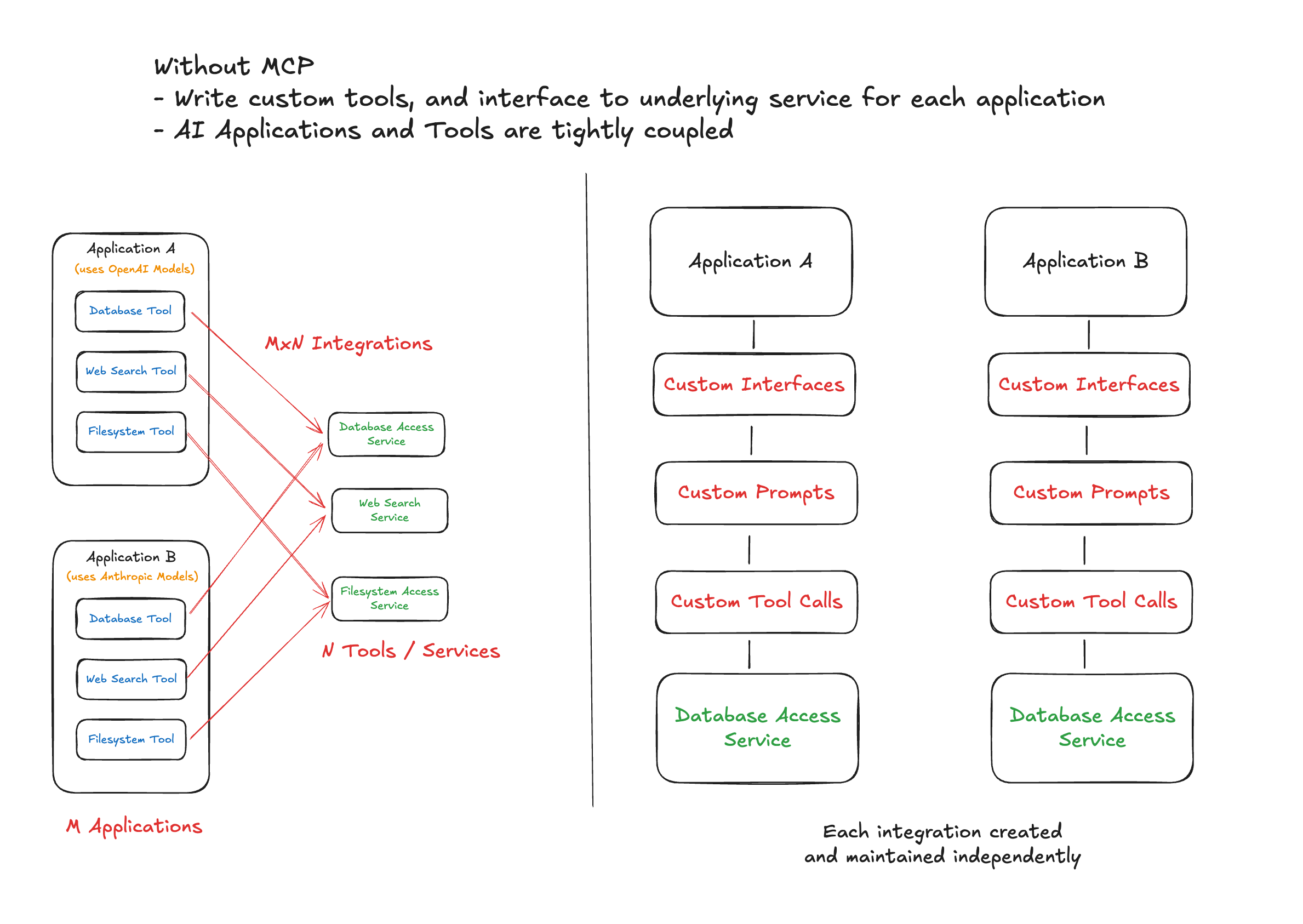
Fragmented AI Development
This way of building agentic applications was exhausting and fragmented. Every external system connection required writing custom tools from scratch. For each integration, developers needed to handle:
- Custom prompts & business logic tailored to each LLM’s expectations
- Connection management to underlying services with different authentication patterns
- Schema translation - tweaking the same tool for different LLMs due to format variations
- Maintenance overhead - a change in an LLM or underlying service meant updating the integrations across the spectrum
This M×N problem created several pain points that became increasingly apparent as the AI ecosystem matured:
Developer Experience Issues:
- Constant context switching between different integration patterns
- Fragile code that broke when providers updated their APIs
- No standardized way to discover available tools
- Duplicated effort across teams building similar integrations
Organizational Scalability Crisis: I cannot stress enough how this approach was not scalable from an organizational perspective. Since tool implementations were tightly coupled with AI features, each team had to own both the feature and the tool - there was no way to have separate teams dedicated just to tools. This created several critical problems:
- No separation of concerns: AI feature teams became bottlenecked by having to also become experts in every external system they needed to integrate
- Expertise dilution: Teams couldn’t specialize - they had to be generalists across AI logic, business requirements, AND external system APIs
- Resource inefficiency: Multiple teams would independently build similar integrations to the same external systems
- Knowledge silos: Tool knowledge was trapped within feature teams, preventing reuse across the organization
- Scaling bottlenecks: Adding new AI features required either expanding existing teams’ scope or duplicating integration work
The AI ecosystem needed a better way to connect applications with tools without all this integration chaos, and Anthropic rose up to the challenge.
The Copy-Paste Problem: An End User’s Perspective
“We were constantly copying and pasting information from external systems into Claude when we needed to work on tasks.”* — MCP Creators in this video
This should hit home for anyone who’s used AI assistants for any extended work. Before MCP, the workflow looked like this: Ask Claude to help with a task, Claude asks for data from your CRM or database or files, you switch to another app to find the data and copy it, paste it back into Claude, then repeat this dance every few minutes. It felt like I was the AI’s assistant instead of the other way around.
With MCP-enabled Claude Desktop, this friction is minimised. Claude can directly access your files, databases, APIs, and tools (based on constraints that you place) without you having to play data courier. It’s one of those “you don’t realize how annoying something was until it’s gone” moments
Model Context Protocol Architecture
MCP follows a client-server architecture that consists of three main components that work together to create a bridge between AI applications and external tools.
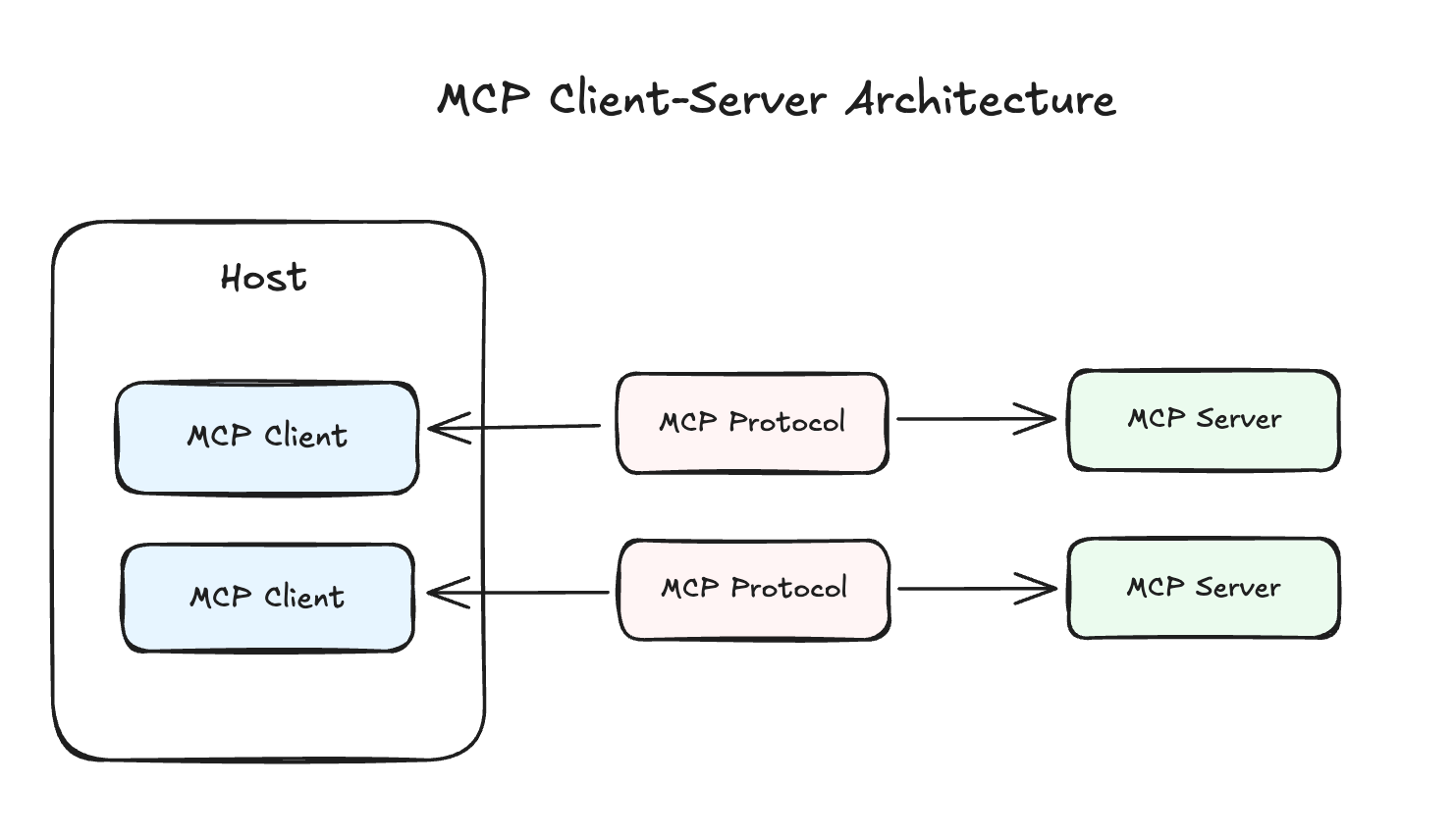
Hosts are the LLM applications that want to access data through MCP - think Claude Desktop, IDEs, or the custom AI agents you’ve built. These hosts contain MCP Clients that maintain 1:1 connections with servers, handling the protocol details so the host application doesn’t need to worry about the underlying communication mechanics.
MCP Servers are programs that each expose specific capabilities through the MCP protocol. Rather than building monolithic integrations, you can deploy focused servers that each handle a particular external system - one for your database, another for your CRM, another for an API endpoints. Or, you can consider building a MCP server that group together these external systems based on your AI applications features. These MCP servers are reusable by various AI applications.
Let’s take a look at MCP Clients and MCP Servers in a bit more detail.
MCP Clients
MCP Clients are the protocol handlers that live within host applications. They’re responsible for invoking tools, querying for resources, and interpolating prompts - essentially acting as the translation layer between your AI application and the MCP server.
MCP Clients provide some key capabilities that enhance the protocol’s functionality. Two important ones are Roots and Sampling.
Roots are URIs that a client can suggest to a server to limit its operational scope. For example, you might specify that a file system server should only operate within specific directories, or that an HTTP server should only access certain endpoints. This provides multiple benefits: enhanced security by limiting server access to only necessary resources, improved clarity by keeping servers focused on relevant data, and versatility since roots work for both file paths and URLs.
Sampling allows servers to request inference from the LLM they’re connected to. More on this in a minute.
MCP Servers
MCP Servers expose three fundamental types of capabilities that work together to create rich, contextual AI interactions. The key capabilities that these servers provide are Tools, Resources, and Prompt Templates.
Tools are functions that can be invoked by the model, for example: retrieving data, sending messages, or updating databases. These are your traditional “function calls” but standardized through the MCP protocol.
Resources work like GET requests - they’re read-only data exposed to the application. The key insight here is that while the resource interface is read-only, the underlying data can still be dynamic. Examples include files, database records, or API responses. Using resources instead of tools creates better separation of concerns, much like how REST APIs distinguish between data retrieval and data modification endpoints.
Prompt Templates might be the most underrated feature of MCP. These are pre-defined templates for AI interactions that shift the prompt engineering burden from AI application developers to MCP server builders. Instead of every developer having to figure out the optimal way to prompt for document Q&A or transcript summarization, the server can provide battle-tested templates that work consistently across different use cases.
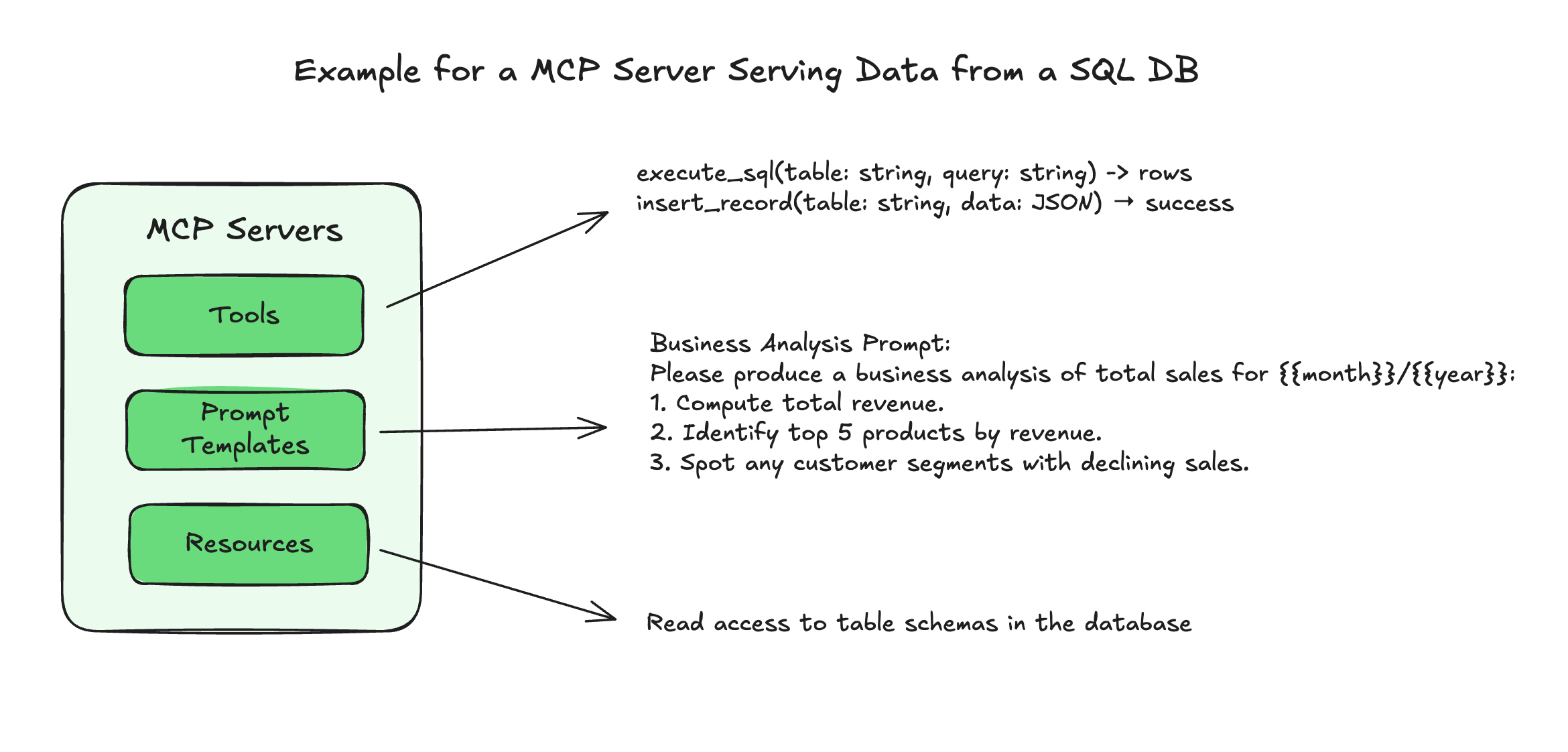
MCP Concepts
Without going into a lot of details, there are several concepts to be aware of when building MCP Servers, or AI applications that interact with them.
Transports
A transport handles the underlying mechanics of how messages are sent and received between client and server. MCP offers several transport options depending on your deployment needs.
For servers running locally, stdio transport is the simplest option. It uses standard input and output streams, making it perfect for desktop applications and command-line tools with zero network overhead.
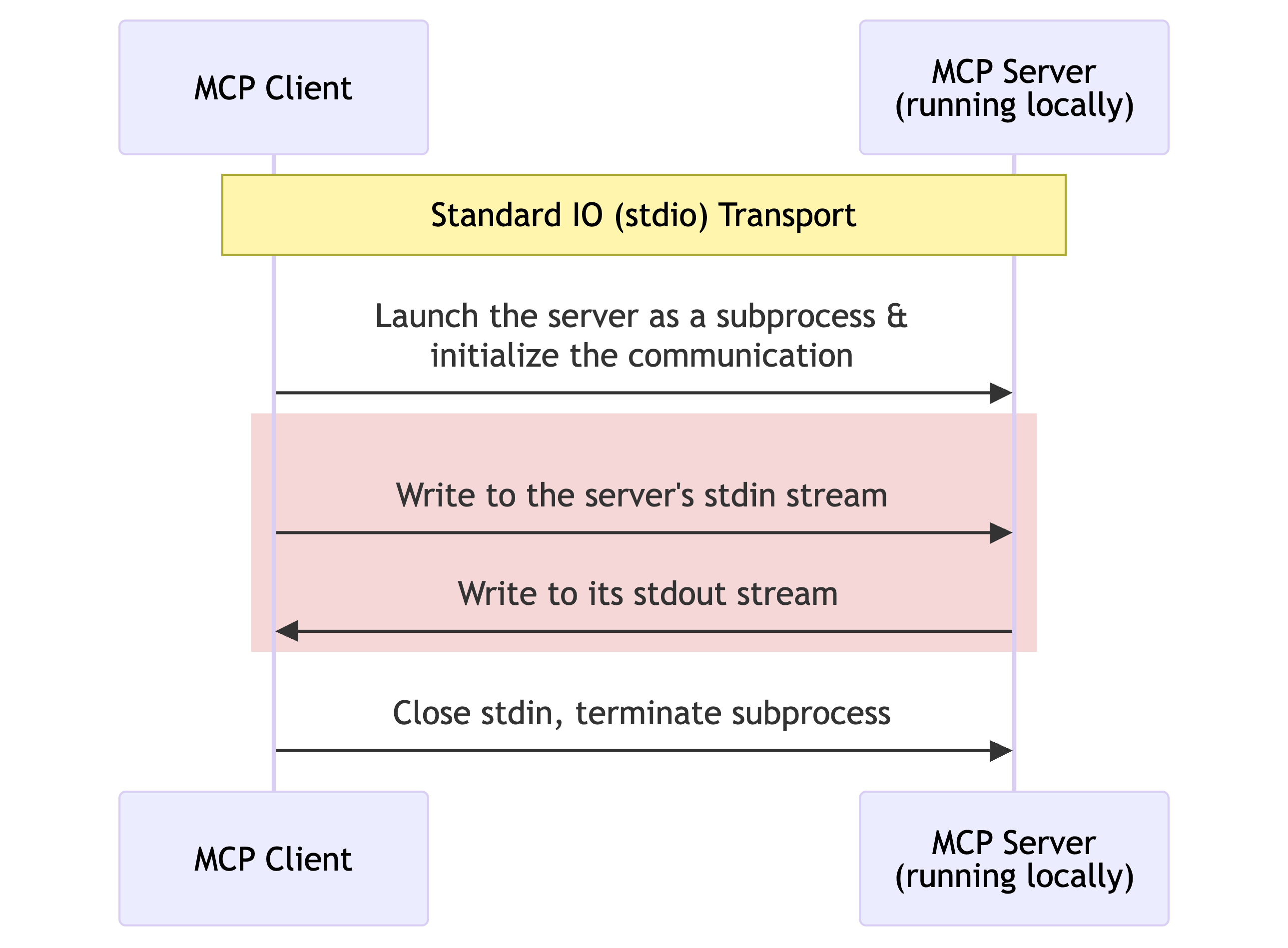 Sequence diagram showcasing the Stdio Transport for MCP.
Sequence diagram showcasing the Stdio Transport for MCP.
For remote servers, MCP supports two HTTP-based transports. Server-Sent Events (SSE) provides HTTP-based communication with real-time capabilities and bidirectional communication. At the time of writing, SSE has since been deprecated and is in the process of being phased out by most MCP Servers.
Streamable HTTP is the modern replacement for SSE and offers better deployment flexibility and supports both stateless and streaming operations. This transport is useful when you need the reliability of HTTP but want to maintain the real-time characteristics that make MCP powerful.
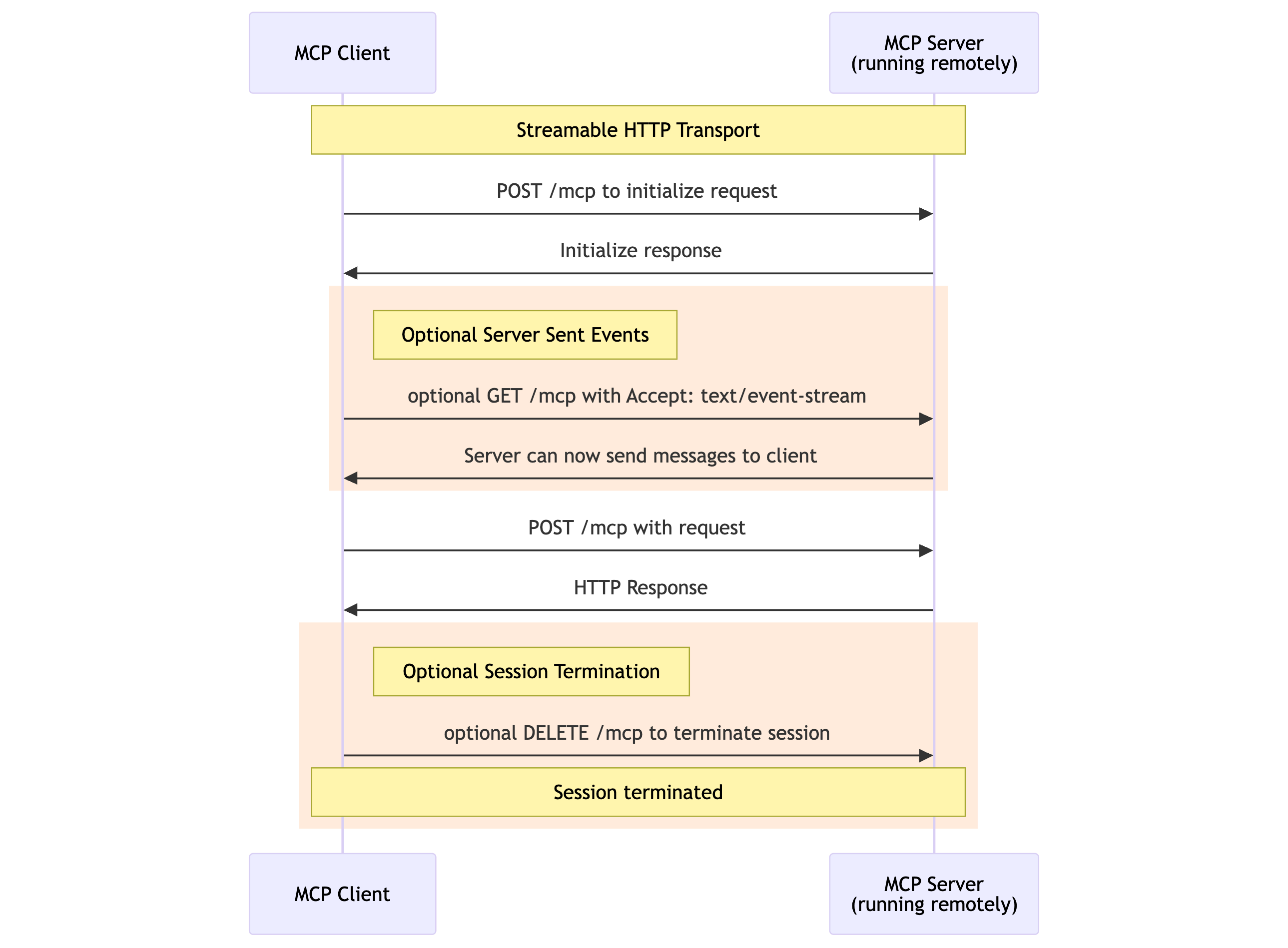 Sequence diagram showcasing the Streamable HTTP Transport for MCP.
Sequence diagram showcasing the Streamable HTTP Transport for MCP.
Sampling
Sampling represents an inversion of the traditional client-server relationship. Instead of clients always requesting services from servers, sampling allows servers to request completions from clients, giving the user application full control over security, privacy, and cost.
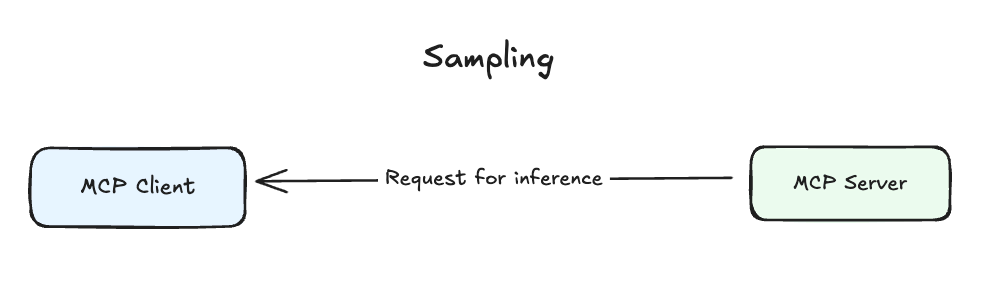
The client handles LLM connections, model selection, and inference management, while the server can specify model preferences, system prompts, temperature settings, and token limits. This creates a powerful pattern where servers can leverage the intelligence of the connected LLM as part of their processing pipeline without needing to manage LLM infrastructure themselves.
Composability
An MCP client can also be a server, and vice versa. This composability enables complex, multi-layered architectures where different components can interact in sophisticated ways.
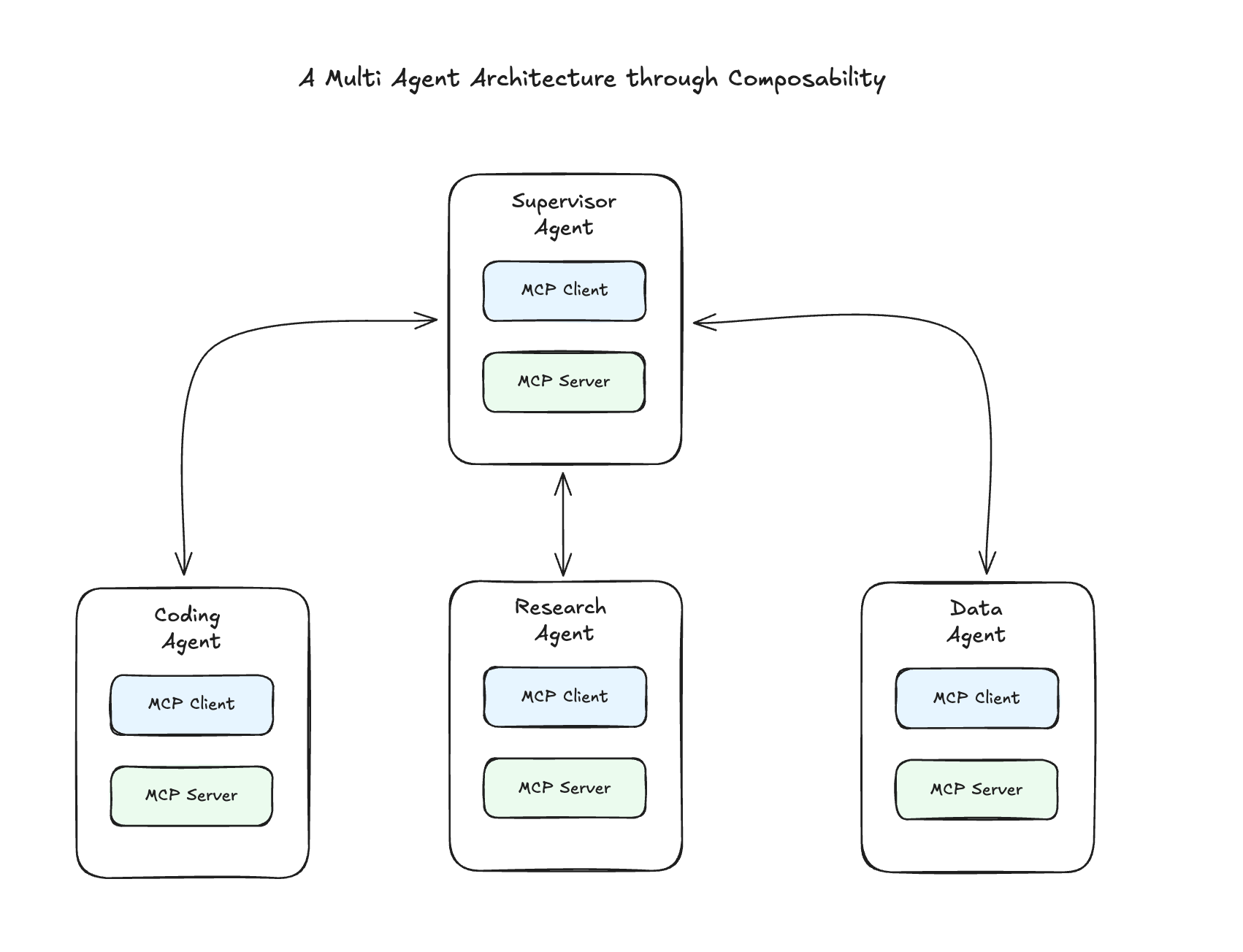
When you combine sampling with composability, you get truly powerful patterns. A server can receive a request, use sampling to get an LLM completion, process that result, and then forward it to another server in a chain. This creates processing pipelines that leverage both AI intelligence and traditional computational resources.
Authorization
MCP’s authorization approach depends on which transport you’re using. For STDIO transport (MCP servers hosted ocally), you simply use environment variables - the MCP server reads service credentials from the environment and handles API authentication behind the scenes.
For HTTP-based transports, MCP implements OAuth 2.1 with specific security requirements. The protocol supports Dynamic Client Registration, allowing clients to automatically obtain credentials without manual setup.
MCP servers choose which OAuth grant types to support based on their use case. Authorization Code flow works when acting on behalf of human users (like accessing someone’s GitHub repos), while Client Credentials flow suits application-to-application scenarios.
For Authorization Code flows, PKCE is mandatory to prevent code interception attacks. PKCE works by having the client generate a random “code verifier”, send a hash of it during authorization, then provide the original verifier when exchanging the code for tokens - ensuring only the legitimate client can complete the flow.
A World with MCPs
Rapid Adoption
Since its launch in November 2024, MCP has seen significant adoption across the AI ecosystem. The protocol has grown to over 7,000 active MCP servers (source: smithery.ai) across community directories, with major AI providers including OpenAI, Google, and Microsoft adding support despite being competitors to Anthropic, the protocol’s creator.
The viral moment came in February 2025 during the AI Engineer Summit, where an MCP workshop garnered over 200,000 combined views across platforms. The community response has been unprecedented, with over thousands of community-built servers appearing on GitHub and new integrations being published daily.
What makes MCP’s adoption truly remarkable is how quickly major AI providers have embraced it - even competitors to Anthropic, the protocol’s creator. OpenAI’s adoption in March 2025 was particularly significant, with CEO Sam Altman stating: “People love MCP and we are excited to add support across our products.” This represented a rare moment of industry alignment, where competing companies recognized the mutual benefit of standardization. Others have followed suite, including Google and Microsoft.
Enterprise adoption has followed, an example being Block (Square) deploying MCP company-wide across their engineering, data, and design teams.
Standardized AI Development
MCP fundamentally changes how we architect AI applications by solving the M×N integration problem. Instead of requiring M AI applications × N external tools custom integrations (M×N complexity), MCP creates a standardized interface that reduces this to M + N: each AI application connects to MCP once, and each external system exposes one MCP server.
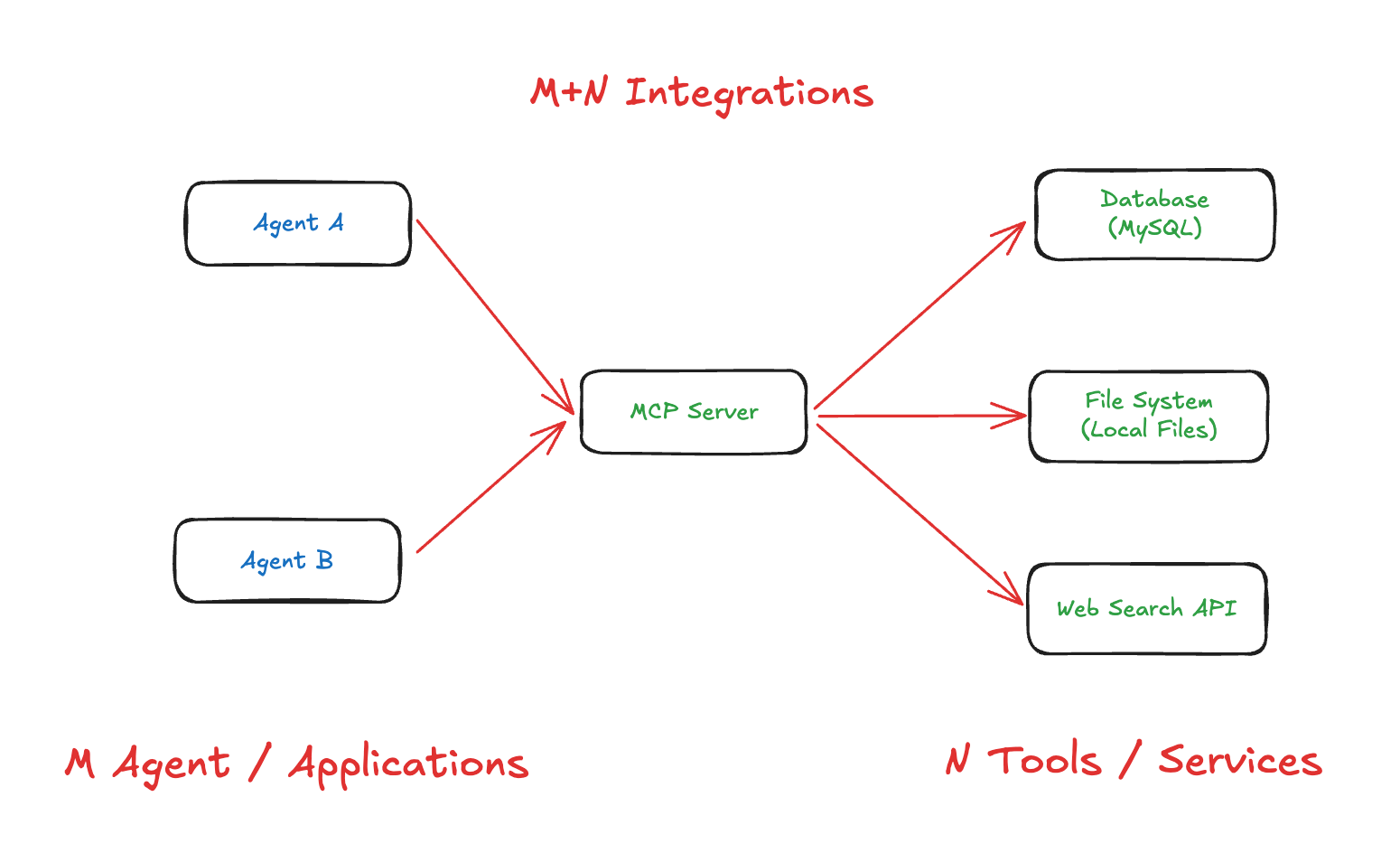
This architectural shift means rather than each AI application implementing its own database connectivity, file system access, or API integrations, we can leverage a shared ecosystem of standardized servers. The standardization extends beyond just tools - MCP servers can provide the entire integration package including prompts, resources, and tools that work consistently across different AI applications.
A good example is DBHub, a universal database gateway that implements the MCP server interface. Instead of building custom database connectors for PostgreSQL, MySQL, SQLite, and other databases in every AI application, DBHub provides a single MCP server that can connect to and explore different databases. Any MCP-compatible client can now access multiple database types through this standardized interface.
Since MCP servers are decoupled from AI applications, agents can be extended even after deployment. You can build an MCP server once (or use community-built ones) and plug them into any MCP-compatible system - whether that’s Claude Desktop, a custom agent built with LangGraph, or the OpenAI Agent SDK.
MCP vs Function Calling: When to Choose What
Does function calling still have a place in the AI ecosystem? The decision between MCP and traditional function calling depends on your specific use case, organizational structure, and performance requirements.
Function calling makes sense when you’re building simple, single-purpose applications where the tight coupling between your AI logic and external systems isn’t a problem. If you’re working with a single LLM provider, have a small team that can manage the integration complexity, and need maximum performance with minimal latency, traditional function calling might be the right choice. The direct integration approach eliminates the protocol overhead and gives you complete control over the implementation.
MCP becomes valuable when you’re building multiple AI applications that need similar capabilities or want to leverage community-built integrations. If you need to support multiple LLM providers, have separate teams handling AI features versus infrastructure, or want to future-proof your architecture for unknown future requirements, MCP’s standardized approach pays dividends. The protocol’s decoupling allows for better separation of concerns and easier maintenance as your system grows. As mentioned previously in the blog post, there’s a high chance that an MCP server already exists to connect to your external service of choice.
The performance trade-off is real but typically manageable. MCP adds 10-50ms per call compared to direct function calling, which is negligible for most applications but could matter for high-frequency, low-latency use cases. However, the architectural benefits of standardization, reusability, and maintainability usually outweigh this small performance cost, especially as applications scale beyond simple prototypes.
MCP Server Directory and Tooling
Official GitHub Registry
The primary MCP ecosystem centers around Anthropic’s GitHub repository, which hosts reference implementations and community servers covering everything from file system access to enterprise software integrations. Installation is straightforward through package managers like npx for Node.js servers or uvx for Python servers.
Community Directories Several community-driven directories have emerged to organize the growing collection of MCP servers. Smithery (smithery.ai) has become the leading registry, hosting over 7,000 capabilities across thousands of servers with one-click CLI installation that integrates with Claude Desktop and Cursor. Other notable directories include MCP Registry (mcpregistry.click) as a unified ecosystem source and PulseMCP (pulsemcp.com), which curates over 1,700 servers with weekly updates on new releases.
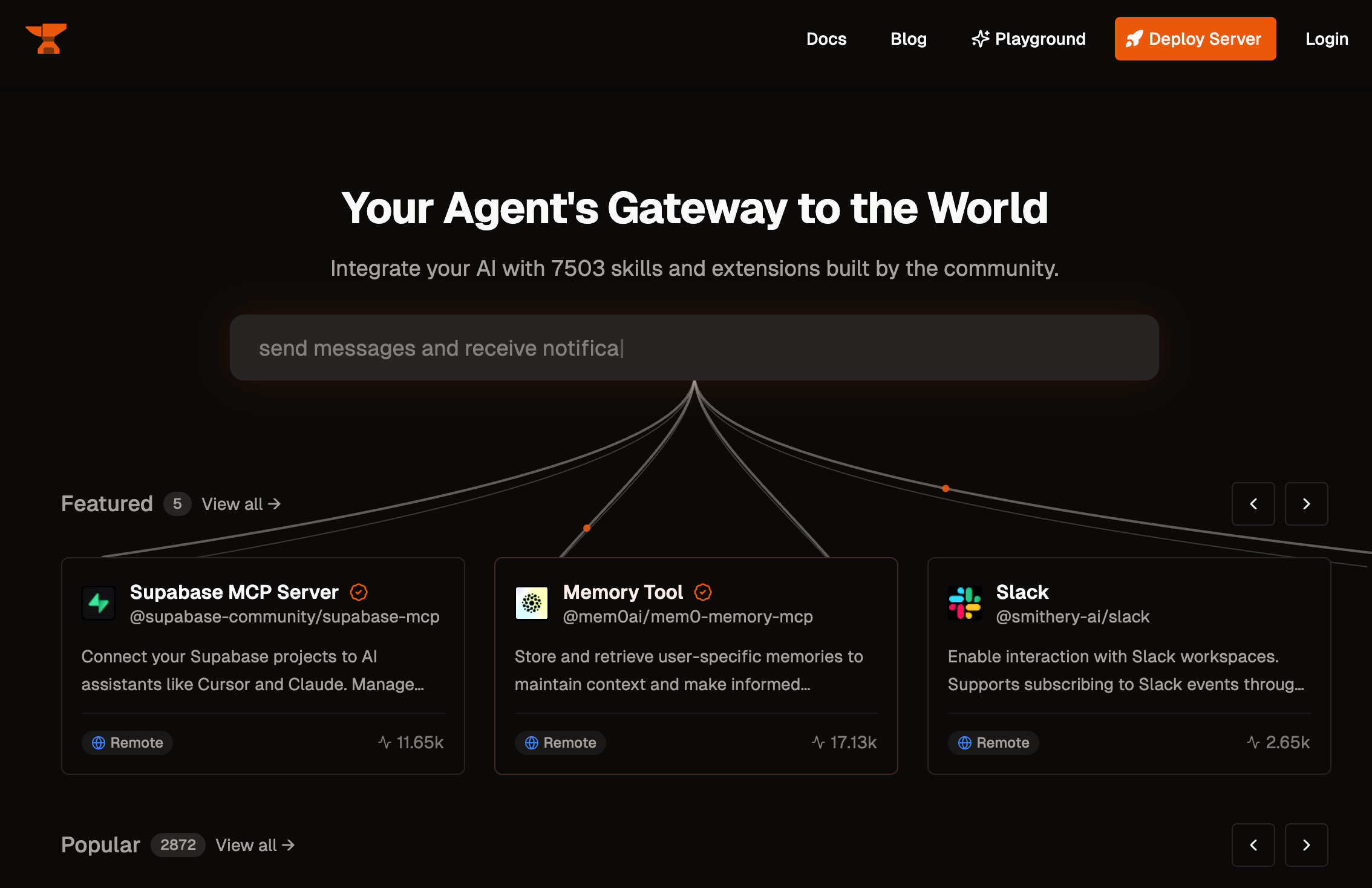 Smithery directory showcasing over 7,000 skills and extensions exposed through MCP servers
Smithery directory showcasing over 7,000 skills and extensions exposed through MCP servers
Development Tools The development ecosystem includes essential tools like MCP Inspector for debugging server development and FastMCP for rapid prototyping. Official SDKs are available for TypeScript, Python, Java, C#, Swift, and Rust, with templates and boilerplates available for common use cases. Whether building simple file access or complex API integrations, developers can typically find a starting point to customize.
MCP Client Integration Most popular AI agent frameworks now have official MCP client integrations, making it easy to connect your agents to MCP servers. LangGraph provides native MCP support through their client libraries, while frameworks like CrewAI, AutoGen, and the OpenAI Agent SDK include built-in MCP connectivity. This means you don’t need to build MCP clients from scratch - your framework of choice likely already has the integration tools you need to connect to the server ecosystem.
Practical Impact This directory ecosystem means developers can often find pre-built servers instead of building custom integrations. Community-maintained servers leverage collective expertise from specialists who understand those integrations deeply, providing battle-tested implementations that extend beyond just development speed to include optimization and reliability that would be difficult to achieve independently.
Conclusion
The Model Context Protocol addresses a core problem in AI application development: the complexity of connecting models to external systems. By standardizing how AI applications access tools, resources, and data, MCP reduces integration complexity from M×N custom connections to M+N standardized interfaces.
The adoption pattern speaks for itself. Major AI providers have implemented support despite being competitors, thousands of community servers have emerged, and enterprise deployments are becoming common. This suggests MCP is filling a genuine need in the AI development ecosystem rather than just being another protocol.
For developers, MCP offers practical benefits: reduced integration work, access to community-built servers, and the ability to extend AI applications after deployment. The organizational benefits are equally significant - teams can specialize in either AI features or infrastructure without being forced to handle both.
Whether you’re building a simple AI tool or scaling an enterprise platform, MCP provides a path to more maintainable and extensible AI applications. The protocol handles the integration complexity so you can focus on the AI capabilities that matter to your users.