Table of contents
Open Table of contents
Introduction
Welcome to the second post in my Agentic RAG series! In my previous post on “An Introduction to Agentic RAG”, I explored various Agentic RAG patterns and workflows including Query Analysis, Query Rewriting, Multi-Step Retrieval, and Self-Evaluation through Reflection. I also demonstrated how these patterns come together to create sophisticated architectures like Single Agent Router, Corrective RAG, and Adaptive RAG.
This post focuses specifically on implementing one of those architectures: an Agentic RAG workflow with a Router Agent that intelligently determines the most appropriate data source for each query. This addresses one of the fundamental limitations of traditional RAG systems—their reliance on a single, predetermined retrieval source that might not be optimal for every type of query.
Consider a user asking both historical questions (“When was Manchester United founded?”) and current event queries (“Who are Manchester United looking to sign next season?”). A traditional RAG system using only Wikipedia would excel at the historical question but fail on the current events query. Conversely, using only web search might provide up-to-date information but miss well-established historical facts that don’t prominently appear in recent web content.
The Query Router pattern solves this challenge by analyzing each incoming query and directing it to the most appropriate knowledge source—Wikipedia for historical information, web search for current events. This not only improves answer quality but also reduces hallucinations that occur when LLMs try to fill knowledge gaps with fabricated information.
In this blog post, I’ll demonstrate how to implement such a system using LangGraph. I have chosen LangGraph for this tutorial because it allows us to build graph-based workflows that are easy to reason about debug.
You can find a Python notebook for this post here.
Set Up
We’ll use LangGraph (and thus, Langchain) as our orchestration framework, OpenAI API for the chat completions, and both Wikipedia and Tavily for our retrieval sources.
Setting Up the Environment
First, let’s install the necessary libraries:
pip install langgraph langchain langchain_openai langchain_communityImports
import os
from langchain_community.retrievers import WikipediaRetriever, TavilySearchAPIRetriever
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.documents.base import Document
from langchain_openai import ChatOpenAI
from langgraph.graph import START, END, StateGraphDon’t forget to set your API keys:
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["TAVILY_API_KEY"] = "your-tavily-api-key"Building a Simple RAG Pipeline with Wikipedia
Before diving into our more complex agentic workflow, let’s first set up a simple RAG pipeline using LangGraph and Wikipedia as our retrieval source. Unlike LangChain’s pre-packaged chains that combine retrieval and generation steps, we’ll deconstruct the RAG pipeline into distinct nodes within a graph-based workflow.
Our RAG workflow will look like this:
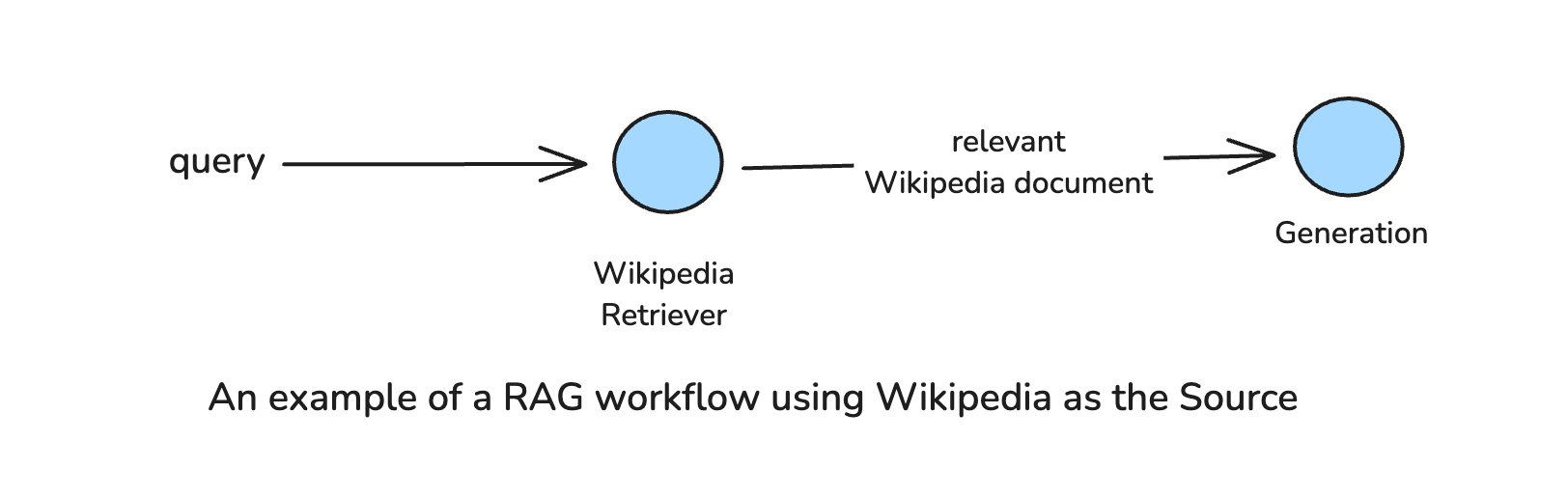
First, we need to define our graph state:
from typing import TypedDict, List
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
query: A string representing the user's query.
retrieved_docs: A list of Document objects retrieved from the Wikipedia retriever.
answer: A string representing the final answer to the user's query.
"""
query: str
retrieved_docs: List[Document]
answer: strNext, let’s create a node for retrieving information from Wikipedia:
# Create a Wikipedia retriever
wikipedia_retriever = WikipediaRetriever()
def retrieve_from_wikipedia(state: GraphState) -> GraphState:
"""
Retrieves documents from Wikipedia based on the query.
Args:
state: A dictionary containing the state of the graph.
Returns:
Updated state with retrieved documents.
"""
print("*** Running Node: Retrieve from Wikipedia ***")
retrieved_docs = wikipedia_retriever.invoke(state["query"])
return {"retrieved_docs": retrieved_docs}Now, we’ll create a node for generating answers based on the retrieved documents:
rag_prompt = """You are an AI assistant. Your main task is to answer questions based on retrieved context.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {query}
Context: {context}
Answer:
"""
rag_prompt_template = ChatPromptTemplate.from_template(rag_prompt)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
generation_answer_chain = rag_prompt_template | llm | StrOutputParser()
def generate_answer_with_retrieved_documents(state: GraphState) -> GraphState:
"""Node to generate answer using retrieved documents"""
print("*** Running Node: Generate Answer with Retrieved Documents ***")
query = state["query"]
documents = state["retrieved_docs"]
answer = generation_answer_chain.invoke({"query": query, "context": documents})
return {"answer": answer}With our nodes defined, we can now compile our basic RAG graph:
def compile_graph():
workflow = StateGraph(GraphState)
### add the nodes
workflow.add_node("retrieve_wikipedia", retrieve_from_wikipedia)
workflow.add_node("generate_answer", generate_answer_with_retrieved_documents)
## build graph
workflow.set_entry_point("retrieve_wikipedia")
workflow.add_edge("retrieve_wikipedia", "generate_answer")
workflow.add_edge("generate_answer", END)
## compile graph
return workflow.compile()
app = compile_graph()
def response_from_graph(query: str):
return app.invoke({"query": query})["answer"]Let’s test our basic RAG pipeline with a historical query:
print(response_from_graph("When was Manchester United founded?"))Output:
*** Running Node: Retrieve from Wikipedia ***
*** Running Node: Generate Answer with Retrieved Documents ***
Manchester United was founded as Newton Heath LYR Football Club in 1878.Great! Now let’s try a query that requires up-to-date information:
print(response_from_graph("Who are Manchester United looking to sign next season?"))Output:
*** Running Node: Retrieve from Wikipedia ***
*** Running Node: Generate Answer with Retrieved Documents ***
I don't know who Manchester United is looking to sign next season, as the provided context does not include information about their transfer targets.As expected, our Wikipedia-based RAG pipeline cannot handle queries about current events or recent developments. This limitation highlights the need for an agentic approach that can select the appropriate retrieval source based on the query type.
Building an Agentic RAG Workflow with Query Router and Web Search
To address the limitations of our basic RAG pipeline, we’ll now build an agentic RAG workflow that can intelligently route queries to the most appropriate retrieval source. The key components of this enhanced workflow are:
- A Query Router: An LLM-based component that analyzes the query and determines whether to use Wikipedia or a web search retriever.
- Multiple Retrieval Sources: Wikipedia for historical information and Tavily Search API for current events.
- Conditional Edges: Logic that directs the flow based on the router’s decision.
After we’re finished, the workflow will look like this:
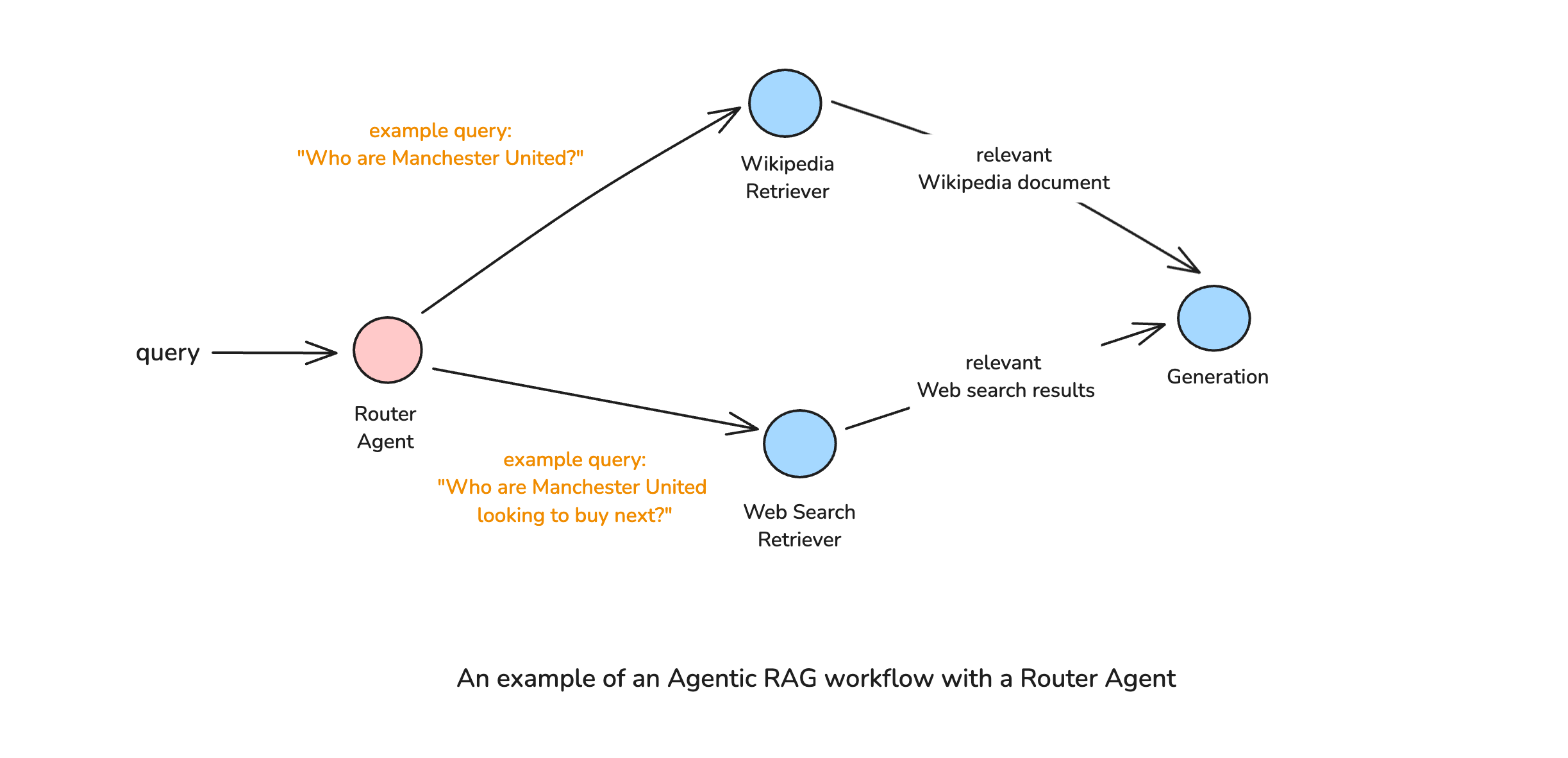
Let’s start by adding a web search retriever using the Tavily API:
from langchain_community.retrievers import TavilySearchAPIRetriever
tavily_retriever = TavilySearchAPIRetriever(k=3)
def retrieve_from_web_search(state: GraphState) -> GraphState:
"""
Retrieves documents from web search based on the query.
Args:
state: A dictionary containing the state of the graph.
Returns:
Updated state with retrieved documents.
"""
print("*** Running Node: Retrieve from Web Search ***")
retrieved_docs = tavily_retriever.invoke(state["query"])
return {"retrieved_docs": retrieved_docs}Next, let’s create our query router using a structured output chain:
from pydantic import BaseModel, Field
class RouterOutput(BaseModel):
"""Schema for router output"""
chosen_retriever: str = Field(description="The name of the chosen retriever. Either 'wikipedia' or 'web_search'")
router_prompt = """
You are a helpful assistant that can determine which retriever to use based on the query.
If a given query is about a topic based on historical context, output "wikipedia".
If a given query is about a topic based on current events, output "web_search".
Query: {query}
"""
router_prompt_template = PromptTemplate.from_template(router_prompt)
llm_with_router_output = llm.with_structured_output(RouterOutput)
router_chain = router_prompt_template | llm_with_router_outputLet’s test our router chain:
# Historical query
router_chain.invoke({"query": "What is Manchester United?"})
# Output: RouterOutput(chosen_retriever='wikipedia')
# Current events query
router_chain.invoke({"query": "Who are Manchester United looking to sign next season?"})
# Output: RouterOutput(chosen_retriever='web_search')Now, we need to update our graph state to include the chosen retriever:
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
chosen_retriever: A string representing the chosen retriever ('wikipedia' or 'web_search').
query: A string representing the user's query.
retrieved_docs: A list of Document objects retrieved from the Wikipedia retriever.
answer: A string representing the final answer to the user's query.
"""
chosen_retriever: str
query: str
retrieved_docs: List[Document]
answer: strWe’ll create a router node and a routing function for our conditional edge:
def query_router(state: GraphState) -> GraphState:
"""
Determines which retriever to use based on the query.
Args:
state: A dictionary containing the state of the graph.
Returns:
Updated state with retrieved documents.
"""
print("*** Running Node: Query Router ***")
chosen_retriever = router_chain.invoke({"query": state["query"]}).chosen_retriever
print(f"Chosen retriever: {chosen_retriever}")
return {"chosen_retriever": chosen_retriever}
def routing_function(state: GraphState) -> str:
"""Conditional edge for the routing function which decides the next node to execute."""
return state["chosen_retriever"]Finally, we can compile our agentic RAG graph with the query router:
def compile_agentic_rag_graph():
workflow = StateGraph(GraphState)
### add the nodes
workflow.add_node("query_router", query_router)
workflow.add_node("retrieve_wikipedia", retrieve_from_wikipedia)
workflow.add_node("retrieve_web_search", retrieve_from_web_search)
workflow.add_node("generate_answer", generate_answer_with_retrieved_documents)
## build graph
workflow.set_entry_point("query_router")
workflow.add_conditional_edges(
"query_router",
routing_function,
{
"wikipedia": "retrieve_wikipedia",
"web_search": "retrieve_web_search"
}
)
workflow.add_edge("retrieve_wikipedia", "generate_answer")
workflow.add_edge("retrieve_web_search", "generate_answer")
workflow.add_edge("generate_answer", END)
## compile graph
return workflow.compile()
app = compile_agentic_rag_graph()
def response_from_graph(query: str):
return app.invoke({"query": query})["answer"]Let’s test our agentic RAG workflow with both historical and current events queries:
# Historical query
print(response_from_graph("When was Manchester United incorporated?"))Output:
*** Running Node: Query Router ***
Chosen retriever: wikipedia
*** Running Node: Retrieve from Wikipedia ***
*** Running Node: Generate Answer with Retrieved Documents ***
Manchester United was incorporated in 1902 when the club changed its name from Newton Heath LYR Football Club to Manchester United.# Current events query
print(response_from_graph("Who are Manchester United looking to sign next?"))Output:
*** Running Node: Query Router ***
Chosen retriever: web_search
*** Running Node: Retrieve from Web Search ***
*** Running Node: Generate Answer with Retrieved Documents ***
Manchester United are looking to sign Ipswich Town's Liam Delap, who is understood to be their number one target with a £30m release clause.Amazing! Our agentic RAG workflow can now intelligently route queries to the most appropriate retrieval source, resulting in more accurate and relevant answers for both historical and current events queries.
Conclusion
In this blog post, we’ve explored the concept of an Agentic RAG Workflow with a Query Router, implemented using LangGraph. By incorporating an intelligent routing mechanism, our RAG system can dynamically select the most appropriate retrieval source based on the nature of the query, significantly enhancing its versatility and accuracy.
The key advantages of this approach include:
- Improved Answer Quality: By routing queries to the most appropriate data source, we ensure that the LLM has the most relevant and up-to-date information available.
- Reduced Hallucinations: With access to appropriate and current information, the LLM is less likely to fabricate answers when faced with knowledge gaps.
- System Flexibility: The graph-based workflow can be easily extended to include additional retrieval sources, making the system highly adaptable to various use cases.
We can extend our router to handle more specific retrieval sources, such as code repositories for programming questions, academic databases for research inquiries, or specialized knowledge bases for domain-specific questions. We could also incorporate more sophisticated routing logic that considers not just the query type but also factors like source reliability, recency, and user preferences. These kinds of signals, extracted from the query and user preferences, are a part of almost all retrieval-based systems.
As RAG systems continue to evolve, incorporating agentic components like query routers will become increasingly important for building AI systems that can effectively navigate and leverage the vast landscape of available information.
References
- LangGraph Documentation: https://python.langchain.com/docs/langgraph
- Introduction to Agentic RAG by Sajal Sharma